Linux内核学习——内存管理之内存区管理
阅读内存区管理之前,需要先掌握页框管理机制。优先阅读《Linux内核学习——内存管理之页框管理》。
Linux内存管理——内存区管理
buddy system以page frame作为单位,这适合大块内存的请求,对于小请求来说,如果每次对几十字节的请求都分配一个page frame显然是极大的浪费。Linux当然需要一套机制来管理每个页框的详细内存分配。
Slab Allocator Design
源于Solaris 2.4的一种设计,ULK给的定义非常晕,实际上只需要一张图即可搞清楚设计的架构。详细的情况需要看源码。
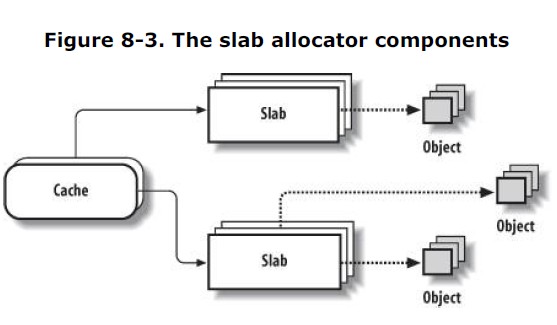
cache和slab的关系: 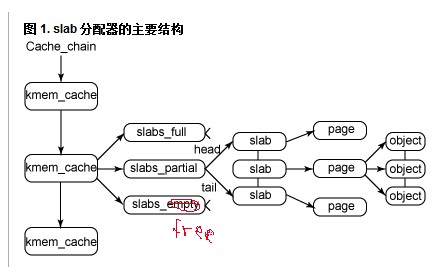
每个cache都包含三个slabs列表,这是一段连续的内存块。存在3种slab: full:完全分配的slab partial:部分分配的slab free:空slab,对象没被分配
slab列表中的每个slab都是一个连续的内存块,它们被划分成一个个分类的对象。slab是slab分配器操作的最小分配单位,通常情况,一个slab被分配成多个对象。
深入探索三个列表的工作机理前,先看看它们的描述符结构定义。
Cache描述符
kmem_cache_s就是cache的描述符结构: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131/**
* 高速缓存描述符
*/
struct kmem_cache_s {
/* 1) per-cpu data, touched during every alloc/free */
/**
* 每CPU指针数组,指向包含空闲对象的本地高速缓存。
*/
struct array_cache *array[NR_CPUS];
/**
* 要转移进本地高速缓存或从本地高速缓存中转移出的大批对象的数量。
*/
unsigned int batchcount;
/**
* 本地高速缓存中空闲对象的最大数目。这个参数可调。
*/
unsigned int limit;
/* 2) touched by every alloc & free from the backend */
/**
* 包含三个链表,为什么要单独放到一个描述符中呢?
*/
struct kmem_list3 lists;
/* NUMA: kmem_3list_t *nodelists[MAX_NUMNODES] */
/**
* 高速缓存中包含的对象的大小。
*/
unsigned int objsize;
/**
* 描述高速缓存永久属性的一组标志。
*/
unsigned int flags; /* constant flags */
/**
* 在一个单独slab中的对象的个数。高速缓存中的所有slab具有相同的大小。
*/
unsigned int num; /* # of objs per slab */
/**
* 整个slab高速缓存中空闲对象的上限。
*/
unsigned int free_limit; /* upper limit of objects in the lists */
/**
* 高速缓存自旋锁。
*/
spinlock_t spinlock;
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
/**
* 一个单独slab中包含的连续页框数目的对数。
*/
unsigned int gfporder;
/* force GFP flags, e.g. GFP_DMA */
/**
* 分配页框时传递给伙伴系统函数的一组标志。
*/
unsigned int gfpflags;
/**
* slab使用的颜色个数。用于slab着色。
*/
size_t colour; /* cache colouring range */
/**
* slab中的基本对齐偏移。
*/
unsigned int colour_off; /* colour offset */
/**
* 下一个被分配的slab使用的颜色。就是对齐因子。
*/
unsigned int colour_next; /* cache colouring */
/**
* 指向包含slab描述符的普通slab高速缓存。如果使用了内部slab描述符,则这个字段为NULL。
*/
kmem_cache_t *slabp_cache;
/**
* 单个slab的大小。
* slab_size = slab描述符大小 + 所有对象描述符大小 + pading
*/
unsigned int slab_size;
/**
* 高速缓存动态属性标志。
*/
unsigned int dflags; /* dynamic flags */
/* constructor func */
/**
* 高速缓存相关的构造方法的指针。
*/
void (*ctor)(void *, kmem_cache_t *, unsigned long);
/* de-constructor func */
/**
* 高速缓存相关的析构方法的指针。
*/
void (*dtor)(void *, kmem_cache_t *, unsigned long);
/* 4) cache creation/removal */
/**
* 高速缓存名称。
*/
const char *name;
/**
* 高速缓存链表。
*/
struct list_head next;
/* 5) statistics */
#if STATS
/**
* 统计信息
*/
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#endif
#if DEBUG
/**
* 调试信息
*/
int dbghead;
int reallen;
#endif
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* 空闲对象的本地高速缓存描述符(注意:是描述符而不是本地高速缓存本身,本地高速缓存在描述符后面)
*/
struct array_cache {
/**
* 指向本地高速缓存中可使用对象的指针的个数。
* 它同时也作为高速缓存中第一个空槽的下标。
*/
unsigned int avail;
/**
* 本地高速缓存的大小,也就是本地高速缓存中指针的最大个数
*/
unsigned int limit;
/**
* 本地高速缓存重新填充或者腾空时使用的块大小
*/
unsigned int batchcount;
/**
* 如果最近被使用过,则置为1
*/
unsigned int touched;
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/**
* slab高速缓存描述符内嵌结构
*/
struct kmem_list3 {
/**
* 空闲和非空闲对象的slab描述符双向循环链表。
*/
struct list_head slabs_partial; /* partial list first, better asm code */
/**
* 不包含空闲对象的slab描述符双向循环链表。
*/
struct list_head slabs_full;
/**
* 只包含空闲对象的slab描述符双向循环链表。
*/
struct list_head slabs_free;
unsigned long free_objects;
/**
* slab分配器的页回收算法使用。
*/
int free_touched;
/**
* slab分配器的页回收算法使用。
*/
unsigned long next_reap;
/**
* 所有CPU共享的一个本地高速缓存的指针。它使得将空闲对象从一个本地高速缓存移动到另外一个高速缓存的任务更容易。
* 它的初始大小是batchcount字段的8倍。
*/
struct array_cache *shared;
};
对象都是在slab中进行分配释放的,单个slab可以在slab列表之间移动。比如当一个slab中所有对象都被用完时,就从partial链移动到full链;当一个slab完全被分配并且有对象被释放后,就从full链移动到partial链。在看完slab描述符后,会有一张图用于梳理工作逻辑与结构关系。
slab描述符
高速缓存中的每个slab都由自己的类型为slab的描述符: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* slab描述符
*/
struct slab {
/**
* slab高速缓存描述符的三个双向循环链表中的一个。
*/
struct list_head list;
/**
* slab中第一个对象的偏移。
* 同一个高速缓存的不同slab有不同的coloroff值。这样可以避免硬件缓存行的不利影响。
*/
unsigned long colouroff;
/**
* slab中第一个对象的地址。
*/
void *s_mem; /* including colour offset */
/**
* 当前正在使用的slab中的对象个数。
*/
unsigned int inuse; /* num of objs active in slab */
/**
* slab中下一个空闲对象的下标。如果没有剩下空闲对象则为BUFCT_END
*/
kmem_bufctl_t free;
};CFLGS_OFF_SLAB置1。
-
放在slab内部,位于分配给slab的第一个页框的起始位置。当对象小于512MB,或者当内部碎片为slab描述符和对象描述符在slab中留下足够空间时,slab描述符放在内部。
ULK上cache描述符与slab描述符的关联: 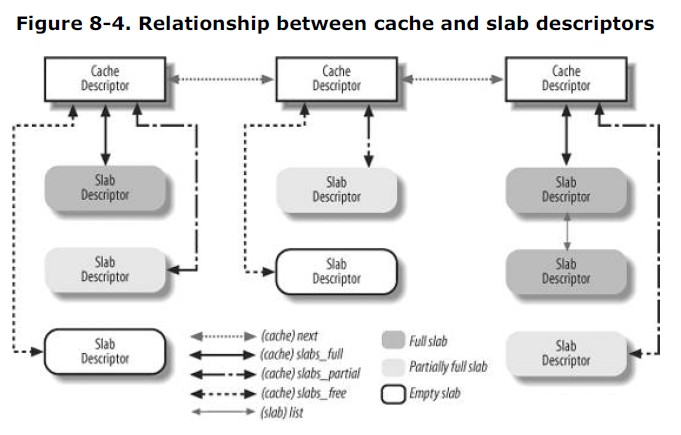
三种slab链的工作机理: 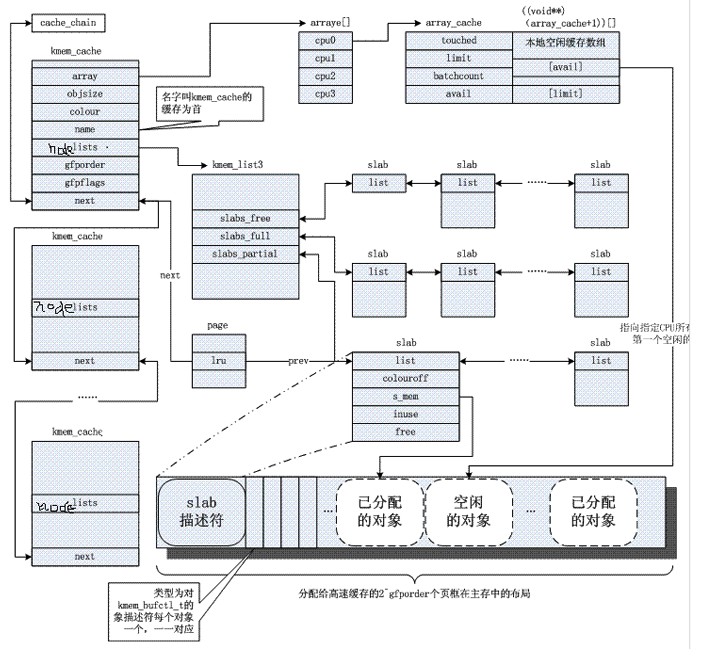
slab的内部结构平坦视图: 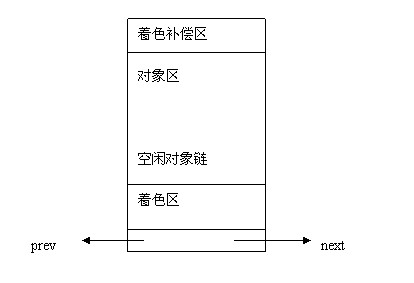
关于着色相关,后面再详述。
普通和专用高速缓存
高速缓存的两种类型。普通只由slab分配器用于自己的目的,专用则由内核其余部分使用。
普通高速缓存: 1.
第一个高速缓存是kmem_cache,包含由内核使用的其余高速缓存的高速缓存描述符。cache_cache变量包含第一个高速缓存的描述符。
2.
另外一些高速缓存包含用作普通用途的内存区。内存区大小的范围一般包括13个几何分布的内存区。一个叫做malloc_sizes的表分别指向26个高速缓存描述符,相关的内存区大小为32,64,128,256,512,1024,2048,4096,8192,16384,32768,65536,131072字节。对每种大小,都有两个高速缓存:一个适用于ISA
DMA分配,一个用于常规分配。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/**
* 第一个普通高速缓存
*/
static kmem_cache_t cache_cache = {
.lists = LIST3_INIT(cache_cache.lists),
.batchcount = 1,
.limit = BOOT_CPUCACHE_ENTRIES,
.objsize = sizeof(kmem_cache_t),
.flags = SLAB_NO_REAP,
.spinlock = SPIN_LOCK_UNLOCKED,
.name = "kmem_cache",
#if DEBUG
.reallen = sizeof(kmem_cache_t),
#endif
};
/**
* 指向26个高速缓存描述符的表。
* 与其相关的内存区大小为32,64,128,256,512,1024,4096,8192,32768,131072个字节。
* 对于每种大小,都有两个高速缓存:一个适用于ISA DMA分配,一个适用于常规分配。
*/
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include <linux/kmalloc_sizes.h>
{ 0, }
#undef CACHE
};
/* Size description struct for general caches. */
struct cache_sizes {
size_t cs_size;
kmem_cache_t *cs_cachep;
kmem_cache_t *cs_dmacachep;
};
普通高速缓存的初始化建立: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122/**
* 建立普通高速缓存。
*/
void __init kmem_cache_init(void)
{
size_t left_over;
struct cache_sizes *sizes;
struct cache_names *names;
/*
* Fragmentation resistance on low memory - only use bigger
* page orders on machines with more than 32MB of memory.
*/
if (num_physpages > (32 << 20) >> PAGE_SHIFT)
slab_break_gfp_order = BREAK_GFP_ORDER_HI;
/* Bootstrap is tricky, because several objects are allocated
* from caches that do not exist yet:
* 1) initialize the cache_cache cache: it contains the kmem_cache_t
* structures of all caches, except cache_cache itself: cache_cache
* is statically allocated.
* Initially an __init data area is used for the head array, it's
* replaced with a kmalloc allocated array at the end of the bootstrap.
* 2) Create the first kmalloc cache.
* The kmem_cache_t for the new cache is allocated normally. An __init
* data area is used for the head array.
* 3) Create the remaining kmalloc caches, with minimally sized head arrays.
* 4) Replace the __init data head arrays for cache_cache and the first
* kmalloc cache with kmalloc allocated arrays.
* 5) Resize the head arrays of the kmalloc caches to their final sizes.
*/
/* 1) create the cache_cache */
init_MUTEX(&cache_chain_sem);
INIT_LIST_HEAD(&cache_chain);
list_add(&cache_cache.next, &cache_chain);
cache_cache.colour_off = cache_line_size();
cache_cache.array[smp_processor_id()] = &initarray_cache.cache;
cache_cache.objsize = ALIGN(cache_cache.objsize, cache_line_size());
cache_estimate(0, cache_cache.objsize, cache_line_size(), 0,
&left_over, &cache_cache.num);
if (!cache_cache.num)
BUG();
cache_cache.colour = left_over/cache_cache.colour_off;
cache_cache.colour_next = 0;
cache_cache.slab_size = ALIGN(cache_cache.num*sizeof(kmem_bufctl_t) +
sizeof(struct slab), cache_line_size());
/* 2+3) create the kmalloc caches */
sizes = malloc_sizes;
names = cache_names;
while (sizes->cs_size) {
/* For performance, all the general caches are L1 aligned.
* This should be particularly beneficial on SMP boxes, as it
* eliminates "false sharing".
* Note for systems short on memory removing the alignment will
* allow tighter packing of the smaller caches. */
sizes->cs_cachep = kmem_cache_create(names->name,
sizes->cs_size, ARCH_KMALLOC_MINALIGN,
(ARCH_KMALLOC_FLAGS | SLAB_PANIC), NULL, NULL);
/* Inc off-slab bufctl limit until the ceiling is hit. */
if (!(OFF_SLAB(sizes->cs_cachep))) {
offslab_limit = sizes->cs_size-sizeof(struct slab);
offslab_limit /= sizeof(kmem_bufctl_t);
}
sizes->cs_dmacachep = kmem_cache_create(names->name_dma,
sizes->cs_size, ARCH_KMALLOC_MINALIGN,
(ARCH_KMALLOC_FLAGS | SLAB_CACHE_DMA | SLAB_PANIC),
NULL, NULL);
sizes++;
names++;
}
/* 4) Replace the bootstrap head arrays */
{
void * ptr;
ptr = kmalloc(sizeof(struct arraycache_init), GFP_KERNEL);
local_irq_disable();
BUG_ON(ac_data(&cache_cache) != &initarray_cache.cache);
memcpy(ptr, ac_data(&cache_cache), sizeof(struct arraycache_init));
cache_cache.array[smp_processor_id()] = ptr;
local_irq_enable();
ptr = kmalloc(sizeof(struct arraycache_init), GFP_KERNEL);
local_irq_disable();
BUG_ON(ac_data(malloc_sizes[0].cs_cachep) != &initarray_generic.cache);
memcpy(ptr, ac_data(malloc_sizes[0].cs_cachep),
sizeof(struct arraycache_init));
malloc_sizes[0].cs_cachep->array[smp_processor_id()] = ptr;
local_irq_enable();
}
/* 5) resize the head arrays to their final sizes */
{
kmem_cache_t *cachep;
down(&cache_chain_sem);
list_for_each_entry(cachep, &cache_chain, next)
enable_cpucache(cachep);
up(&cache_chain_sem);
}
/* Done! */
g_cpucache_up = FULL;
/* Register a cpu startup notifier callback
* that initializes ac_data for all new cpus
*/
register_cpu_notifier(&cpucache_notifier);
/* The reap timers are started later, with a module init call:
* That part of the kernel is not yet operational.
*/
}
专用高速缓存创建: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329/**
* 建立专用高速缓存。
*/
kmem_cache_t *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void*, kmem_cache_t *, unsigned long),
void (*dtor)(void*, kmem_cache_t *, unsigned long))
{
size_t left_over, slab_size, ralign;
kmem_cache_t *cachep = NULL;
/*
* Sanity checks... these are all serious usage bugs.
*/
if ((!name) ||
in_interrupt() ||
(size < BYTES_PER_WORD) ||
(size > (1<<MAX_OBJ_ORDER)*PAGE_SIZE) ||
(dtor && !ctor)) {
printk(KERN_ERR "%s: Early error in slab %s\n",
__FUNCTION__, name);
BUG();
}
#if DEBUG
WARN_ON(strchr(name, ' ')); /* It confuses parsers */
if ((flags & SLAB_DEBUG_INITIAL) && !ctor) {
/* No constructor, but inital state check requested */
printk(KERN_ERR "%s: No con, but init state check "
"requested - %s\n", __FUNCTION__, name);
flags &= ~SLAB_DEBUG_INITIAL;
}
#if FORCED_DEBUG
/*
* Enable redzoning and last user accounting, except for caches with
* large objects, if the increased size would increase the object size
* above the next power of two: caches with object sizes just above a
* power of two have a significant amount of internal fragmentation.
*/
/**
* 根据参数确定高速缓存的最佳方法(是内部还是外部slab描述符。)
*/
if ((size < 4096 || fls(size-1) == fls(size-1+3*BYTES_PER_WORD)))
flags |= SLAB_RED_ZONE|SLAB_STORE_USER;
if (!(flags & SLAB_DESTROY_BY_RCU))
flags |= SLAB_POISON;
#endif
if (flags & SLAB_DESTROY_BY_RCU)
BUG_ON(flags & SLAB_POISON);
#endif
if (flags & SLAB_DESTROY_BY_RCU)
BUG_ON(dtor);
/*
* Always checks flags, a caller might be expecting debug
* support which isn't available.
*/
if (flags & ~CREATE_MASK)
BUG();
/* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
if (size & (BYTES_PER_WORD-1)) {
size += (BYTES_PER_WORD-1);
size &= ~(BYTES_PER_WORD-1);
}
/* calculate out the final buffer alignment: */
/* 1) arch recommendation: can be overridden for debug */
/**
* 需要考虑硬件缓存行。
*/
if (flags & SLAB_HWCACHE_ALIGN) {
/* Default alignment: as specified by the arch code.
* Except if an object is really small, then squeeze multiple
* objects into one cacheline.
*/
/**
* 如果高速缓存对象的大小大于高速缓存行ralign的一半,
* 就在RAM中根据L1_CACHE_BYTES的倍数对齐对象。
*
* lf: 很好理解,大于cacheline,一半,就按照整个cacheline对其; 小于一半,一个cacheline至少可以放两个,以cacheline的一半对其
*/
ralign = cache_line_size();
while (size <= ralign/2)
ralign /= 2;
} else {
ralign = BYTES_PER_WORD;
}
/* 2) arch mandated alignment: disables debug if necessary */
if (ralign < ARCH_SLAB_MINALIGN) {
ralign = ARCH_SLAB_MINALIGN;
if (ralign > BYTES_PER_WORD)
flags &= ~(SLAB_RED_ZONE|SLAB_STORE_USER);
}
/* 3) caller mandated alignment: disables debug if necessary */
if (ralign < align) {
ralign = align;
if (ralign > BYTES_PER_WORD)
flags &= ~(SLAB_RED_ZONE|SLAB_STORE_USER);
}
/* 4) Store it. Note that the debug code below can reduce
* the alignment to BYTES_PER_WORD.
*/
align = ralign;
/* Get cache's description obj. */
/**
* 从cache_cache普通高速缓存中为新的高速缓存分配一个高速缓存描述符。
* 并把这个描述符插入到高速缓存描述符的cache_chain链表中。
*/
cachep = (kmem_cache_t *) kmem_cache_alloc(&cache_cache, SLAB_KERNEL);
if (!cachep)
goto opps;
memset(cachep, 0, sizeof(kmem_cache_t));
#if DEBUG
cachep->reallen = size;
if (flags & SLAB_RED_ZONE) {
/* redzoning only works with word aligned caches */
align = BYTES_PER_WORD;
/* add space for red zone words */
cachep->dbghead += BYTES_PER_WORD;
size += 2*BYTES_PER_WORD;
}
if (flags & SLAB_STORE_USER) {
/* user store requires word alignment and
* one word storage behind the end of the real
* object.
*/
align = BYTES_PER_WORD;
size += BYTES_PER_WORD;
}
#if FORCED_DEBUG && defined(CONFIG_DEBUG_PAGEALLOC)
if (size > 128 && cachep->reallen > cache_line_size() && size < PAGE_SIZE) {
cachep->dbghead += PAGE_SIZE - size;
size = PAGE_SIZE;
}
#endif
#endif
/* Determine if the slab management is 'on' or 'off' slab. */
if (size >= (PAGE_SIZE>>3))
/*
* Size is large, assume best to place the slab management obj
* off-slab (should allow better packing of objs).
*/
flags |= CFLGS_OFF_SLAB;
size = ALIGN(size, align);
if ((flags & SLAB_RECLAIM_ACCOUNT) && size <= PAGE_SIZE) {
/*
* A VFS-reclaimable slab tends to have most allocations
* as GFP_NOFS and we really don't want to have to be allocating
* higher-order pages when we are unable to shrink dcache.
*/
cachep->gfporder = 0;
cache_estimate(cachep->gfporder, size, align, flags,
&left_over, &cachep->num);
} else {
/*
* Calculate size (in pages) of slabs, and the num of objs per
* slab. This could be made much more intelligent. For now,
* try to avoid using high page-orders for slabs. When the
* gfp() funcs are more friendly towards high-order requests,
* this should be changed.
*/
do {
unsigned int break_flag = 0;
cal_wastage:
cache_estimate(cachep->gfporder, size, align, flags,
&left_over, &cachep->num);
if (break_flag)
break;
if (cachep->gfporder >= MAX_GFP_ORDER)
break;
if (!cachep->num)
goto next;
if (flags & CFLGS_OFF_SLAB &&
cachep->num > offslab_limit) {
/* This num of objs will cause problems. */
cachep->gfporder--;
break_flag++;
goto cal_wastage;
}
/*
* Large num of objs is good, but v. large slabs are
* currently bad for the gfp()s.
*/
if (cachep->gfporder >= slab_break_gfp_order)
break;
if ((left_over*8) <= (PAGE_SIZE<<cachep->gfporder))
break; /* Acceptable internal fragmentation. */
next:
cachep->gfporder++;
} while (1);
}
if (!cachep->num) {
printk("kmem_cache_create: couldn't create cache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto opps;
}
slab_size = ALIGN(cachep->num*sizeof(kmem_bufctl_t)
+ sizeof(struct slab), align);
/*
* If the slab has been placed off-slab, and we have enough space then
* move it on-slab. This is at the expense of any extra colouring.
*/
if (flags & CFLGS_OFF_SLAB && left_over >= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
if (flags & CFLGS_OFF_SLAB) {
/* really off slab. No need for manual alignment */
slab_size = cachep->num*sizeof(kmem_bufctl_t)+sizeof(struct slab);
}
/*colour_off中记录的aln*/
cachep->colour_off = cache_line_size();
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < align)
cachep->colour_off = align;
/*可用颜色的个数是free/aln*/
cachep->colour = left_over/cachep->colour_off;
cachep->slab_size = slab_size;
cachep->flags = flags;
cachep->gfpflags = 0;
if (flags & SLAB_CACHE_DMA)
cachep->gfpflags |= GFP_DMA;
spin_lock_init(&cachep->spinlock);
cachep->objsize = size;
/* NUMA */
INIT_LIST_HEAD(&cachep->lists.slabs_full);
INIT_LIST_HEAD(&cachep->lists.slabs_partial);
INIT_LIST_HEAD(&cachep->lists.slabs_free);
if (flags & CFLGS_OFF_SLAB)
cachep->slabp_cache = kmem_find_general_cachep(slab_size,0);
cachep->ctor = ctor;
cachep->dtor = dtor;
cachep->name = name;
/* Don't let CPUs to come and go */
lock_cpu_hotplug();
if (g_cpucache_up == FULL) {
/*
* 初始化每CPU本地高速缓存
*/
enable_cpucache(cachep);
} else {
if (g_cpucache_up == NONE) {
/* Note: the first kmem_cache_create must create
* the cache that's used by kmalloc(24), otherwise
* the creation of further caches will BUG().
*/
cachep->array[smp_processor_id()] = &initarray_generic.cache;
g_cpucache_up = PARTIAL;
} else {
cachep->array[smp_processor_id()] = kmalloc(sizeof(struct arraycache_init),GFP_KERNEL);
}
BUG_ON(!ac_data(cachep));
ac_data(cachep)->avail = 0;
ac_data(cachep)->limit = BOOT_CPUCACHE_ENTRIES;
ac_data(cachep)->batchcount = 1;
ac_data(cachep)->touched = 0;
cachep->batchcount = 1;
cachep->limit = BOOT_CPUCACHE_ENTRIES;
cachep->free_limit = (1+num_online_cpus())*cachep->batchcount
+ cachep->num;
}
cachep->lists.next_reap = jiffies + REAPTIMEOUT_LIST3 +
((unsigned long)cachep)%REAPTIMEOUT_LIST3;
/* Need the semaphore to access the chain. */
/*
* 将新分配的高速缓存描述符挂接到cache_chain中
*/
down(&cache_chain_sem);
{
struct list_head *p;
mm_segment_t old_fs;
old_fs = get_fs();
set_fs(KERNEL_DS);
list_for_each(p, &cache_chain) {
kmem_cache_t *pc = list_entry(p, kmem_cache_t, next);
char tmp;
/* This happens when the module gets unloaded and doesn't
destroy its slab cache and noone else reuses the vmalloc
area of the module. Print a warning. */
if (__get_user(tmp,pc->name)) {
printk("SLAB: cache with size %d has lost its name\n",
pc->objsize);
continue;
}
if (!strcmp(pc->name,name)) {
printk("kmem_cache_create: duplicate cache %s\n",name);
up(&cache_chain_sem);
unlock_cpu_hotplug();
BUG();
}
}
set_fs(old_fs);
}
/* cache setup completed, link it into the list */
list_add(&cachep->next, &cache_chain);
up(&cache_chain_sem);
unlock_cpu_hotplug();
opps:
if (!cachep && (flags & SLAB_PANIC))
panic("kmem_cache_create(): failed to create slab `%s'\n",
name);
return cachep;
}
撤销高速缓存: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 撤销一个高速缓存并将它从cache_chain链表上删除
* 主要用于模块中。
*/
int kmem_cache_destroy (kmem_cache_t * cachep)
{
int i;
if (!cachep || in_interrupt())
BUG();
/* Don't let CPUs to come and go */
lock_cpu_hotplug();
/* Find the cache in the chain of caches. */
down(&cache_chain_sem);
/*
* the chain is never empty, cache_cache is never destroyed
*/
list_del(&cachep->next);
up(&cache_chain_sem);
if (__cache_shrink(cachep)) {
slab_error(cachep, "Can't free all objects");
down(&cache_chain_sem);
list_add(&cachep->next,&cache_chain);
up(&cache_chain_sem);
unlock_cpu_hotplug();
return 1;
}
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU))
synchronize_kernel();
/* no cpu_online check required here since we clear the percpu
* array on cpu offline and set this to NULL.
*/
for (i = 0; i < NR_CPUS; i++)
kfree(cachep->array[i]);
/* NUMA: free the list3 structures */
kfree(cachep->lists.shared);
cachep->lists.shared = NULL;
kmem_cache_free(&cache_cache, cachep);
unlock_cpu_hotplug();
return 0;
}__cache_shrink()负责这一工作,实际上就是反复的slab_destroy():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34static int __cache_shrink(kmem_cache_t *cachep)
{
struct slab *slabp;
int ret;
drain_cpu_caches(cachep);
check_irq_on();
spin_lock_irq(&cachep->spinlock);
for(;;) {
struct list_head *p;
p = cachep->lists.slabs_free.prev;
if (p == &cachep->lists.slabs_free)
break;
slabp = list_entry(cachep->lists.slabs_free.prev, struct slab, list);
#if DEBUG
if (slabp->inuse)
BUG();
#endif
list_del(&slabp->list);
cachep->lists.free_objects -= cachep->num;
spin_unlock_irq(&cachep->spinlock);
slab_destroy(cachep, slabp);
spin_lock_irq(&cachep->spinlock);
}
ret = !list_empty(&cachep->lists.slabs_full) ||
!list_empty(&cachep->lists.slabs_partial);
spin_unlock_irq(&cachep->spinlock);
return ret;
}
slab分配器与zoned page frame分配器的接口
slab分配器创建新slab时,它依赖zoned page
frame分配器以获得一组空闲连续页框。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31/*
* slab分配器调用此接口从页框分配器中获得一组连续的空闲页框。
* cachep-需要额外页框的高速缓存的高速缓存描述符。请求页框的个数由cachep->gfporder中的order决定。
* flags-说明如何请求页框。这组标志与存放在高速缓存描述符的gfpflags字段中专用高速缓存分配标志相结合。
*/
static void *kmem_getpages(kmem_cache_t *cachep, int flags, int nodeid)
{
struct page *page;
void *addr;
int i;
flags |= cachep->gfpflags;
if (likely(nodeid == -1)) {
page = alloc_pages(flags, cachep->gfporder);
} else {
page = alloc_pages_node(nodeid, flags, cachep->gfporder);
}
if (!page)
return NULL;
addr = page_address(page);
i = (1 << cachep->gfporder);
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_add(i, &slab_reclaim_pages);
add_page_state(nr_slab, i);
while (i--) {
SetPageSlab(page);
page++;
}
return addr;
}alloc_pages_node,再看释放操作: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/**
* 释放分配给slab的页框。
* addr-从该地址开始释放页框。
* cachep-slab是由cachep标识的高速缓存中的slab.
*/
static void kmem_freepages(kmem_cache_t *cachep, void *addr)
{
unsigned long i = (1<<cachep->gfporder);
struct page *page = virt_to_page(addr);
const unsigned long nr_freed = i;
while (i--) {
if (!TestClearPageSlab(page))
BUG();
page++;
}
sub_page_state(nr_slab, nr_freed);
/**
* 如果当前进程正在执行回存回收。就适当增加reclaimed_slab字段。
* 于是刚被释放的页就能通过回收算法被记录下来。
*/
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += nr_freed;
free_pages((unsigned long)addr, cachep->gfporder);
/**
* 如果SLAB_RECLAIM_ACCOUNT被置位,slab_reclaim_pages则被适当的减少。
*/
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1<<cachep->gfporder, &slab_reclaim_pages);
}free_pages。
slab分配与释放
分配
kmem_cache一开始没有任何slab,三条链都是空的。只有当收到分配新对象的请求或者当前不包含任何空闲对象时才会分配slab。
slab分配器通过cache_grow()给kmem_cache分配新的slab:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107/**
* 给高速缓存分配一个新的slab。
*/
static int cache_grow (kmem_cache_t * cachep, int flags, int nodeid)
{
struct slab *slabp;
void *objp;
size_t offset;
int local_flags;
unsigned long ctor_flags;
/* Be lazy and only check for valid flags here,
* keeping it out of the critical path in kmem_cache_alloc().
*/
if (flags & ~(SLAB_DMA|SLAB_LEVEL_MASK|SLAB_NO_GROW))
BUG();
if (flags & SLAB_NO_GROW)
return 0;
ctor_flags = SLAB_CTOR_CONSTRUCTOR;
local_flags = (flags & SLAB_LEVEL_MASK);
if (!(local_flags & __GFP_WAIT))
/*
* Not allowed to sleep. Need to tell a constructor about
* this - it might need to know...
*/
ctor_flags |= SLAB_CTOR_ATOMIC;
/* About to mess with non-constant members - lock. */
check_irq_off();
spin_lock(&cachep->spinlock);
/* Get colour for the slab, and cal the next value. */
/**
* 更新高速缓存描述符的当前颜色值。并根据当前颜色值计算数据区的偏移。
* 这样可以平等的在slab间分布颜色值。
* offset就是 aln * col, colour_off字段记录的aln,colour_next记录的col
*/
offset = cachep->colour_next;
cachep->colour_next++;
if (cachep->colour_next >= cachep->colour)
cachep->colour_next = 0;
offset *= cachep->colour_off;
spin_unlock(&cachep->spinlock);
if (local_flags & __GFP_WAIT)
local_irq_enable();
/*
* The test for missing atomic flag is performed here, rather than
* the more obvious place, simply to reduce the critical path length
* in kmem_cache_alloc(). If a caller is seriously mis-behaving they
* will eventually be caught here (where it matters).
*/
kmem_flagcheck(cachep, flags);
/* Get mem for the objs. */
/**
* 调用kmem_getpages从分区页框分配器获得一组页框来存放一个单独的slab
*/
if (!(objp = kmem_getpages(cachep, flags, nodeid)))
goto failed;
/* Get slab management. */
/**
* 获得一个新的slab描述符
*/
if (!(slabp = alloc_slabmgmt(cachep, objp, offset, local_flags)))
goto opps1;
/**
* set_slab_attr扫描分配给新slab的页框的所有页描述符
* 并将高速缓存描述符和slab描述符的地址分别赋给页描述符中lru字段的next和prev字段
* 这是不会出错的,因为只有当页框空闲时,伙伴系统的函数才会使用lru字段,而只要涉及伙伴系统,slab分配器函数处理的页框就不空闲。
* 注意:这个字段因为也会被页框回收算法使用,所以包含了这些隐含的约定,总会让人困惑,也许会带来一些意外的后果。
* 总之,从这里可以看出linux不好、甚至是坏的一面。除了linus,还有多少人能够改linux??
*/
set_slab_attr(cachep, slabp, objp);
/**
* cache_init_objs将构造方法(如果有)应用到新的slab包含的所有对象上。
*/
cache_init_objs(cachep, slabp, ctor_flags);
if (local_flags & __GFP_WAIT)
local_irq_disable();
check_irq_off();
spin_lock(&cachep->spinlock);
/* Make slab active. */
/**
* 将新得到的slab描述符slabp添加到高速缓存描述符cachep的全空slab链表的末端。并更新空闲对象计数器
*/
list_add_tail(&slabp->list, &(list3_data(cachep)->slabs_free));
STATS_INC_GROWN(cachep);
list3_data(cachep)->free_objects += cachep->num;
spin_unlock(&cachep->spinlock);
return 1;
opps1:
kmem_freepages(cachep, objp);
failed:
if (local_flags & __GFP_WAIT)
local_irq_disable();
return 0;
}kmem_getpages拿到一组页框。然后通过alloc_slabmgmt获得新的slab描述符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/**
* 获得一个新的slab描述符。
*/
static struct slab* alloc_slabmgmt (kmem_cache_t *cachep,
void *objp, int colour_off, int local_flags)
{
struct slab *slabp;
/**
* 如果CFLGS_OFF_SLAB标志被置位,那么样从高速缓存描述符的slabp_cache字段指向的普通高速缓存中分配这个新的描述符。
*/
if (OFF_SLAB(cachep)) {
/* Slab management obj is off-slab. */
slabp = kmem_cache_alloc(cachep->slabp_cache, local_flags);
if (!slabp)
return NULL;
} else {
/**
* 否则,从slab的第一个页框中分配这个slab描述符
*/
slabp = objp+colour_off;
colour_off += cachep->slab_size; /*slab_size字段记录的就是dsize*/
}
slabp->inuse = 0;
/*将col*aln + dsize存放到colouroff中,aln就是高速缓存描述符的colour_off字段*/
slabp->colouroff = colour_off;
slabp->s_mem = objp+colour_off;
return slabp;
}
分配新slab描述符后,扫描分配给新slab的页框的所有页描述符,将kmem_cache和slab描述符的地址赋给页描述符的lru字段的next和prev。lru在buddy system和slab系统中都有用到,实际上这种设计虽然省了空间,但却称为逻辑的困扰项。
此后的cache_init_objs对新slab的所有对象应用构造方法,然后把新的slab描述符链到free链的尾端,更新对应的字段。
释放
当slab高速缓存中空闲对象太多或周期性调用的定时器函数确定有可以被释放的slab时,才会进行slab的撤销:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73/**
* 当以下两个条件满足时:
* Slab高速缓存中有太多的空闲对象。
* 被定时器周期性的检测到,有完全未使用的slab能够被释放。
* 撤销一个slab。并释放相应的页框到分区页框分配器。
*/
static void slab_destroy (kmem_cache_t *cachep, struct slab *slabp)
{
void *addr = slabp->s_mem - slabp->colouroff;
#if DEBUG
int i;
for (i = 0; i < cachep->num; i++) {
void *objp = slabp->s_mem + cachep->objsize * i;
if (cachep->flags & SLAB_POISON) {
#ifdef CONFIG_DEBUG_PAGEALLOC
if ((cachep->objsize%PAGE_SIZE)==0 && OFF_SLAB(cachep))
kernel_map_pages(virt_to_page(objp), cachep->objsize/PAGE_SIZE,1);
else
check_poison_obj(cachep, objp);
#else
check_poison_obj(cachep, objp);
#endif
}
if (cachep->flags & SLAB_RED_ZONE) {
if (*dbg_redzone1(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "start of a freed object "
"was overwritten");
if (*dbg_redzone2(cachep, objp) != RED_INACTIVE)
slab_error(cachep, "end of a freed object "
"was overwritten");
}
if (cachep->dtor && !(cachep->flags & SLAB_POISON))
(cachep->dtor)(objp+obj_dbghead(cachep), cachep, 0);
}
#else
/**
* 如果高速缓存为它的对象定义了析构方法,就遍历slab中的所有对象。
* 使用析构函数释放slab中的所有对象。
*/
if (cachep->dtor) {
int i;
for (i = 0; i < cachep->num; i++) {
void* objp = slabp->s_mem+cachep->objsize*i;
(cachep->dtor)(objp, cachep, 0);
}
}
#endif
/**
* 如果使用了SLAB_DESTROY_BY_RCU标志来创建slab高速缓存,就应该使用call_rcu
* 来注册一个回调,以延期释放slab。回调函数会调用kmem_freepages和kmem_cache_free
*/
if (unlikely(cachep->flags & SLAB_DESTROY_BY_RCU)) {
struct slab_rcu *slab_rcu;
slab_rcu = (struct slab_rcu *) slabp;
slab_rcu->cachep = cachep;
slab_rcu->addr = addr;
call_rcu(&slab_rcu->head, kmem_rcu_free);
} else {
/**
* 调用kmem_freepages,将slab使用的所有连续页框返回给伙伴系统。
*/
kmem_freepages(cachep, addr);
/**
* 如果slab描述符存放在slab的外面,那么就从slab描述符的高速缓存释放slab描述符。
*/
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->slabp_cache, slabp);
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30/**
* 释放分配给slab的页框。
* addr-从该地址开始释放页框。
* cachep-slab是由cachep标识的高速缓存中的slab.
*/
static void kmem_freepages(kmem_cache_t *cachep, void *addr)
{
unsigned long i = (1<<cachep->gfporder);
struct page *page = virt_to_page(addr);
const unsigned long nr_freed = i;
while (i--) {
if (!TestClearPageSlab(page))
BUG();
page++;
}
sub_page_state(nr_slab, nr_freed);
/**
* 如果当前进程正在执行回存回收。就适当增加reclaimed_slab字段。
* 于是刚被释放的页就能通过回收算法被记录下来。
*/
if (current->reclaim_state)
current->reclaim_state->reclaimed_slab += nr_freed;
free_pages((unsigned long)addr, cachep->gfporder);
/**
* 如果SLAB_RECLAIM_ACCOUNT被置位,slab_reclaim_pages则被适当的减少。
*/
if (cachep->flags & SLAB_RECLAIM_ACCOUNT)
atomic_sub(1<<cachep->gfporder, &slab_reclaim_pages);
}free_pages()释放。
且另一方面,如果slab描述符存放在slab外部,也需要从专门放slab描述符的高速缓存中释放该slab描述符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124/**
* 释放一个曾经由slab分配器分配给某个内核函数的对象
* cachep-高速缓存描述符的地址。
* objp-要释放的对象的地址。
*/
void kmem_cache_free (kmem_cache_t *cachep, void *objp)
{
unsigned long flags;
local_irq_save(flags);
__cache_free(cachep, objp);
local_irq_restore(flags);
}
static inline void __cache_free (kmem_cache_t *cachep, void* objp)
{
struct array_cache *ac = ac_data(cachep);
check_irq_off();
objp = cache_free_debugcheck(cachep, objp, __builtin_return_address(0));
/**
* 首先检查本地高速缓存是否有空间给指向一个空闲对象的额外指针。
*/
if (likely(ac->avail < ac->limit)) {
STATS_INC_FREEHIT(cachep);
/**
* 本地高速缓存有空闲指针,则该指针被加到本地高速缓存后返回。
*/
ac_entry(ac)[ac->avail++] = objp;
return;
} else {
STATS_INC_FREEMISS(cachep);
/**
* 调用cache_flusharray,清空本地高速缓存
*/
cache_flusharray(cachep, ac);
/**
* 然后将指针加到本地高速缓存。
*/
ac_entry(ac)[ac->avail++] = objp;
}
}
/**
* 清空本地高速缓存
*/
static void cache_flusharray (kmem_cache_t* cachep, struct array_cache *ac)
{
int batchcount;
batchcount = ac->batchcount;
#if DEBUG
BUG_ON(!batchcount || batchcount > ac->avail);
#endif
check_irq_off();
/**
* 获得自旋锁
*/
spin_lock(&cachep->spinlock);
/**
* 如果包含一个共享本地高速缓存
*/
if (cachep->lists.shared) {
struct array_cache *shared_array = cachep->lists.shared;
int max = shared_array->limit-shared_array->avail;
/**
* 该共享缓存还没有满
*/
if (max) {
if (batchcount > max)
batchcount = max;
/**
* 将batchcount个指针放到共享高速缓存中。
*/
memcpy(&ac_entry(shared_array)[shared_array->avail],
&ac_entry(ac)[0],
sizeof(void*)*batchcount);
/**
* 上移batchcount个指针来重新填充共享本地高速缓存
*/
shared_array->avail += batchcount;
goto free_done;
}
}
/**
* 将当前包含在本地高速缓存中的ac->batchcount个对象归还给slab分配器。
*/
free_block(cachep, &ac_entry(ac)[0], batchcount);
free_done:
#if STATS
{
int i = 0;
struct list_head *p;
p = list3_data(cachep)->slabs_free.next;
while (p != &(list3_data(cachep)->slabs_free)) {
struct slab *slabp;
slabp = list_entry(p, struct slab, list);
BUG_ON(slabp->inuse);
i++;
p = p->next;
}
STATS_SET_FREEABLE(cachep, i);
}
#endif
/**
* 释放锁
*/
spin_unlock(&cachep->spinlock);
/**
* 通过减去被移到共享本地高速缓存或被释放到slab分配器的对象的个数来更新本地高速缓存描述的avail字段
*/
ac->avail -= batchcount;
/**
* 移动本地高速缓存数组起始处的那个本地高速缓存中的所有指针。
* 因为已经把第一个对象指针从本地高速缓存上删除,因此剩余的指针必须上移。
*/
memmove(&ac_entry(ac)[0], &ac_entry(ac)[batchcount],
sizeof(void*)*ac->avail);
}
如果cachep->flags中指定了SLAB_DESTROY_BY_RCU,就注册kmem_rcu_free回调,延期释放slab
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/**
* rcu原语中,写者调用call_rcu来释放数据结构的旧副本。
* 当所有CPU都经过静止状态(quiescent state)后,
* call_rcu接受rcu_head描述符(通常嵌在要释放在数据结构中)和将要调用的回调函数的地址作为参数。
* 一旦回调函数被执行,它通常释放数据结构的旧副本。
* call_rcu把回调函数和其参数的地址存放在rcu_head,然后把描述符插入到回调函数的每CPU链表中。
* 内核每经过一个时钟滴答,就周期性的检查本地CPU是否经过了一个静止状态。
* 如果经过了,本地tasklet(rcu_tasklet)就执行链表中的回调函数。
*/
void fastcall call_rcu(struct rcu_head *head,
void (*func)(struct rcu_head *rcu))
{
unsigned long flags;
struct rcu_data *rdp;
head->func = func;
head->next = NULL;
local_irq_save(flags);
rdp = &__get_cpu_var(rcu_data);
*rdp->nxttail = head;
rdp->nxttail = &head->next;
local_irq_restore(flags);
}
//注册的回调函数
static void kmem_rcu_free(struct rcu_head *head)
{
struct slab_rcu *slab_rcu = (struct slab_rcu *) head;
kmem_cache_t *cachep = slab_rcu->cachep;
kmem_freepages(cachep, slab_rcu->addr);
if (OFF_SLAB(cachep))
kmem_cache_free(cachep->slabp_cache, slab_rcu);
}kmem_rcu_free函数依然调用的是kmem_freepages挂kmem_cache_free。一样的套路。
Object
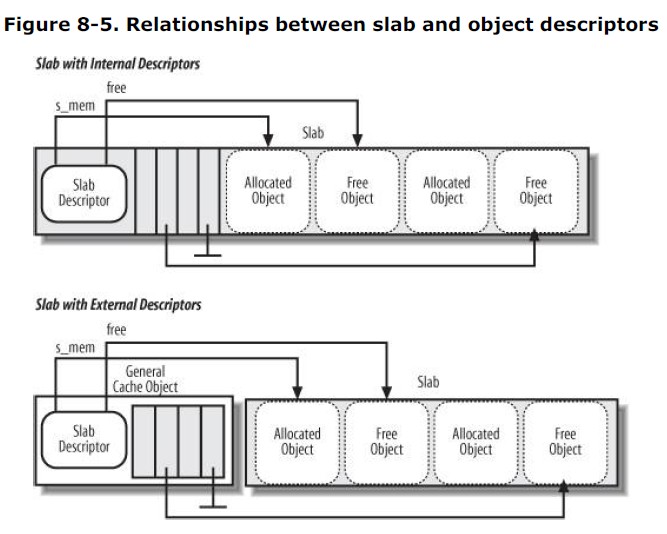
对象描述符
1 | |
kmem_bufctl_t实际上就是个uint16,只有当object空闲时才有意义,表示下一个空闲对象在slab中的下标。通过这一描述符形成了隐式链表,最后一个空闲对象用BUFCTL_END(0xffff)标记#define BUFCTL_END (((kmem_bufctl_t)(~0U))-0)。
因为slab描述符有内部或外部之分,而object描述符跟着slab描述符走(注意这里说的是描述符,而不是object或是slab,object始终在slab内),所以object描述符也有内外之分。 - 外部的object描述符由外部的slab描述符所在的普通高速缓存中的slabp_cache字段指向,它是一个数组。 - 内部的object描述符就位于所有对象之前。
对象对齐
object在内存中是对齐的,起始物理地址是一个给定常量的倍数,通常是2的倍数。该常量称为对齐因子。
slab分配器允许的最大对齐因子为4096,即页框大小。
80x86指定32位大小来对齐对象,因为当内存单元的物理地址对齐尺寸和内存总线宽度一致时,内存的读写会非常快。slab分配器为了对齐,难免会产生额外的内存碎片,但瑕不掩瑜,这代价是值得的。
slab着色
回看这张图:
每个slab的首部都有一个着色区,不为对象使用。着色区的大小使slab中每个对象的起始地址都按高速缓存中缓存行(cache line)大小进行对齐。slab是一组页框,因此slab肯定是按高速缓存行对齐的,但是slab的object大小是不确定的,设置着色区的目的就是将lab中第一个对象的起始地址往后推到与缓冲行对齐的位置。因为一个缓冲区中有多个slab,因此应该把每个缓冲区中的各个slab着色区的大小尽量安排成不同的大小,这就可以使得在不同slab中,出于同一相对位置的对象,让它们在高速缓存中的起始地址相互错开,以改善高速缓存的存取效率(如果不错开,可能同缓存区的两个slab上,同相对位置的两个对象会来来回回在高速缓存行与RAM之间传送,高速缓存行无法发挥效率)。
每个slab上最后也有一片废料区,是对着色区大小的补偿,大小取决于着色区的大小,以及slab与其每个对象的相对大小。该区域和着色区的综合对于同一个对象的各个slab来说是个constant。
每个对象的大小基本上是所需数据结构的大小,只有当数据结构大小不与高速缓存中的缓冲行对齐时,才增加若干字节使其对齐。所以,一个slab上的所有对象的起始地址都必然是按高速缓冲中的缓冲行对齐的。
也就是说,着色区保证了第一个对象的对齐,而对象大小的对齐保证了后续所有对象的对齐。
空闲slab对象的本地缓存
多处理的slab分配器实现不同于原始的Solaris 2.4。为了减少处理器之间对自旋锁的竞争并更好的利用硬件缓存,slab分配器的每个高速缓存都包含一个每CPU数据结构。该结构由一个指向被释放对象的小指针数组组成。slab对象的大多数分配和释放只影响本地数组,只有在本地数组下溢或上溢时才涉及slab数据结构。
这就是kmem_cache的array_cache,前面已经展开看到过。这一设计非常类似“每CPU页框高速缓存”。
分配slab对象
1 | |
如果本地高速缓存有空闲对象,则递减ac->avail值即可,avail包含指向最后被释放的对象的项在本地高速缓存中的下标。if分支的逻辑很简单。
如果没有的话,进入else,就需要通过cache_alloc_refill:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169/**
* 重新填充本地高速缓存并获得一个空闲对象
*/
static void* cache_alloc_refill(kmem_cache_t* cachep, int flags)
{
int batchcount;
struct kmem_list3 *l3;
struct array_cache *ac;
check_irq_off();
/**
* ac = cachep->array[smp_processor_id()];
* 将本地高速缓存描述符的地址存放在ac局部变量中。
*/
ac = ac_data(cachep);
retry:
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/* if there was little recent activity on this
* cache, then perform only a partial refill.
* Otherwise we could generate refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
l3 = list3_data(cachep);
BUG_ON(ac->avail > 0);
/**
* 获取spinlock
*/
spin_lock(&cachep->spinlock);
/**
* 如果slab高速缓存包含共享本地高速缓存
*/
if (l3->shared) {
struct array_cache *shared_array = l3->shared;
/**
* 并且该共享本地高速缓存包含一些空闲对象
*/
if (shared_array->avail) {
if (batchcount > shared_array->avail)
batchcount = shared_array->avail;
/**
* 从共享本地高速缓存中上移batchcount个指针来重新填充CPU的本地高速缓存
*/
shared_array->avail -= batchcount;
ac->avail = batchcount;
/*
* 共享本地高速缓存,从后向前使用,avail指向最后面
* 这里shared_array->avail在前面经过"shared_array->avail -= batchcount;"的处理指向了前面,
* 所以这里直接用memcpy进行从前向后的拷贝
*/
memcpy(ac_entry(ac), &ac_entry(shared_array)[shared_array->avail],
sizeof(void*)*batchcount);
shared_array->touched = 1;
goto alloc_done;
}
}
/**
* 函数试图填充本地高速缓存,填充值为高速缓存的slab中包含的多达ac->batchcount个空闲对象的指针
*/
while (batchcount > 0) {
struct list_head *entry;
struct slab *slabp;
/* Get slab alloc is to come from. */
entry = l3->slabs_partial.next;
/**
* 查看高速缓存描述符的slabs_partial和slabs_free链表
*/
if (entry == &l3->slabs_partial) { /*partial用完了*/
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free) /*free用完了*/
goto must_grow;
}
/**
* 获得slab描述符的地址slabp,该slab描述符的相应slab或者部分被填充或者为空。
*/
slabp = list_entry(entry, struct slab, list);
check_slabp(cachep, slabp);
check_spinlock_acquired(cachep);
/**
* 对于slab中的每个空闲对象
*/
while (slabp->inuse < cachep->num && batchcount--) {
kmem_bufctl_t next;
STATS_INC_ALLOCED(cachep);
STATS_INC_ACTIVE(cachep);
STATS_SET_HIGH(cachep);
/* get obj pointer */
/**
* 将对象地址插入本地高速缓存。
*/
ac_entry(ac)[ac->avail++] = slabp->s_mem + slabp->free*cachep->objsize;
/**
* 函数增加slab描述符的inuse字段
*/
slabp->inuse++;
next = slab_bufctl(slabp)[slabp->free];
#if DEBUG
slab_bufctl(slabp)[slabp->free] = BUFCTL_FREE;
#endif
/**
* 更新free字段,使得它指向slab中下一个空闲对象的下标。
*/
slabp->free = next;
}
check_slabp(cachep, slabp);
/* move slabp to correct slabp list: */
/**
* 如果有必要,将清空的slab插入到适当的链表上,可以是slabs_full链表,也可以是slabs_partial链表
*/
list_del(&slabp->list);
if (slabp->free == BUFCTL_END)
list_add(&slabp->list, &l3->slabs_full);
else
list_add(&slabp->list, &l3->slabs_partial);
}
must_grow:
/**
* 被加到本地高速缓存的指针个数被存放在ac->avail字段。
* 函数递减同样数量的free_objects来说明这些对象不再空闲
*/
l3->free_objects -= ac->avail;
alloc_done:
/**
* 释放spinlock
*/
spin_unlock(&cachep->spinlock);
/**
* 没有发生任何高速缓存再填充的情况
*/
if (unlikely(!ac->avail)) {
int x;
/**
* 调用cache_grow获得一个新的slab,从而获得了新的空闲对象
*/
x = cache_grow(cachep, flags, -1);
// cache_grow can reenable interrupts, then ac could change.
ac = ac_data(cachep);
/**
* cache_grow失败了,返回NULL
*/
if (!x && ac->avail == 0) // no objects in sight? abort
return NULL;
/**
* cache_grow成功了,返回再试。
*/
if (!ac->avail) // objects refilled by interrupt?
goto retry;
}
/**
* 如果ac->avail>0(一些高速缓存再填充的情况发生了)
*/
ac->touched = 1;
/**
* 返回最后插入到本地高速缓存的空闲对象指针
* 本地高速缓存(非共享),从后像前使用,avail指向最后面
*/
return ac_entry(ac)[--ac->avail];
}
释放slab对象
1 | |
较之alloc简单一些,同样的道理,alloc是多对一,而free是一对一。free时当发现本地高速缓存已满,就先清一波,再将本次的对象放进去。
通用对象
如果对存储区的请求不频繁,就可以用一组普通高速缓存来处理,普通高速缓存中的对象具有几何分布的大小,范围是32-131072字节。
kmalloc用于获取这种对象: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60/**
* 获得普通高速缓存中的对象。
*/
static inline void *kmalloc(size_t size, int flags)
{
if (__builtin_constant_p(size)) {
int i = 0;
/**
* 找size对应的几何分布大小值。
*/
#define CACHE(x) \
if (size <= x) \
goto found; \
else \
i++;
#include "kmalloc_sizes.h"
/**
* 运行到此,说明要分配的对象太大,不能分配这么大的对象。
*/
#undef CACHE
{
extern void __you_cannot_kmalloc_that_much(void);
__you_cannot_kmalloc_that_much();
}
/**
* 请求分配的size对应的高速缓存描述符索引号为i
* 根据GFP_DMA,在不同的高速缓存描述符中分配对象。
*/
found:
return kmem_cache_alloc((flags & GFP_DMA) ?
malloc_sizes[i].cs_dmacachep :
malloc_sizes[i].cs_cachep, flags);
}
/*
* 主要走这里,只有内置的常量分配才会走上面
*/
return __kmalloc(size, flags);
}
void * __kmalloc (size_t size, int flags)
{
struct cache_sizes *csizep = malloc_sizes;
/* 在malloc_sizes表中为size匹配最近的2的幂数大小的内存 */
for (; csizep->cs_size; csizep++) {
if (size > csizep->cs_size)
continue;
#if DEBUG
/* This happens if someone tries to call
* kmem_cache_create(), or kmalloc(), before
* the generic caches are initialized.
*/
BUG_ON(csizep->cs_cachep == NULL);
#endif
/* 最终落实到__cache_alloc,GFP_DMA标志在这里处理,决定用csizep对应的dmacache还是级常规cache */
return __cache_alloc(flags & GFP_DMA ?
csizep->cs_dmacachep : csizep->cs_cachep, flags);
}
return NULL;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22/**
* 释放由kmalloc接口分配的内存
*/
void kfree (const void *objp)
{
kmem_cache_t *c;
unsigned long flags;
if (!objp)
return;
local_irq_save(flags);
kfree_debugcheck(objp);
/**
* 通过((kmem_cache_t *)(pg)->lru.next),可确定合适的高速缓存描述符。
*/
c = GET_PAGE_CACHE(virt_to_page(objp));
/**
* __cache_free释放高速缓存中的对象。
*/
__cache_free(c, (void*)objp);
local_irq_restore(flags);
}lru.next字段,就可以确定合适的高速缓存描述符。最终落实到__cache_free释放。
内存池 mempool_t
动态内存最后的储备,内核手头保留的应急罐头。它和保留页框池显然是两回事。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38/**
* 内存池描述符
*/
typedef struct mempool_s {
/**
* 用来保护对象字段的自旋锁。
*/
spinlock_t lock;
/**
* 内存池中元素的最大个数。内存池元素的初始个数
*/
int min_nr; /* nr of elements at *elements */
/**
* 当前内存池中元素的个数。
*/
int curr_nr; /* Current nr of elements at *elements */
/**
* 指向一个数组的指针,该数组由指向保留元素的指针组成。
*/
void **elements;
/**
* 池的拥有者可获得的私有数据。
*/
void *pool_data;
/**
* 分配一个元素的方法。
*/
mempool_alloc_t *alloc;
/**
* 释放一个元素的方法。
*/
mempool_free_t *free;
/**
* 当内存池为空时使用的等待队列。
*/
wait_queue_head_t wait;
} mempool_t;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
/**
* 创建一个新内存池
* min_nr-内存元素的个数。
* alloc_fn,free_fn-分配和释放内存的方法地址。
* pool_data-私有数据。
*/
mempool_t * mempool_create(int min_nr, mempool_alloc_t *alloc_fn,
mempool_free_t *free_fn, void *pool_data)
{
mempool_t *pool;
pool = kmalloc(sizeof(*pool), GFP_KERNEL);
if (!pool)
return NULL;
memset(pool, 0, sizeof(*pool));
pool->elements = kmalloc(min_nr * sizeof(void *), GFP_KERNEL);
if (!pool->elements) {
kfree(pool);
return NULL;
}
spin_lock_init(&pool->lock);
pool->min_nr = min_nr;
pool->pool_data = pool_data;
init_waitqueue_head(&pool->wait);
pool->alloc = alloc_fn;
pool->free = free_fn;
/*
* First pre-allocate the guaranteed number of buffers.
*/
while (pool->curr_nr < pool->min_nr) {
void *element;
element = pool->alloc(GFP_KERNEL, pool->pool_data);
if (unlikely(!element)) {
free_pool(pool);
return NULL;
}
add_element(pool, element);
}
return pool;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
/**
* 从内存池中分配一个元素
*/
void * mempool_alloc(mempool_t *pool, int gfp_mask)
{
void *element;
unsigned long flags;
DEFINE_WAIT(wait);
int gfp_nowait = gfp_mask & ~(__GFP_WAIT | __GFP_IO);
might_sleep_if(gfp_mask & __GFP_WAIT);
repeat_alloc:
/**
* 首先试图通过调用alloc函数从基本内存分配器分配一个内存元素。
*/
element = pool->alloc(gfp_nowait|__GFP_NOWARN, pool->pool_data);
/**
* 如果从基本内存分配器中分配成功,就返回获得的内存元素而不涉及到内存池。
*/
if (likely(element != NULL))
return element;
/*
* If the pool is less than 50% full and we can perform effective
* page reclaim then try harder to allocate an element.
*/
mb();
/**
* 从基本内存池中分配元素失败,从内存池中分配。
*/
/**
* 如果内存池中的对象太少,并且允许阻塞,就试图从基本内存分配器分配。
*/
if ((gfp_mask & __GFP_FS) && (gfp_mask != gfp_nowait) &&
(pool->curr_nr <= pool->min_nr/2)) {
element = pool->alloc(gfp_mask, pool->pool_data);
if (likely(element != NULL))
return element;
}
/*
* Kick the VM at this point.
*/
wakeup_bdflush(0);
/**
* 运行到此,就真的需要从内存池中取得元素了。
* 要么是从基本内存池中分配失败,要么是内存池中的元素还比较多。
*/
spin_lock_irqsave(&pool->lock, flags);
if (likely(pool->curr_nr)) {
element = remove_element(pool);
spin_unlock_irqrestore(&pool->lock, flags);
return element;
}
spin_unlock_irqrestore(&pool->lock, flags);
/* We must not sleep in the GFP_ATOMIC case */
/**
* 内存池中的对象也用完了。又不允许等待,那就返回NULL吧。
*/
if (!(gfp_mask & __GFP_WAIT))
return NULL;
/**
* 内存池中的元素用完了,但是允许等待,由于前面已经唤醒了守护进程。
* 现在需要的是让守护线程运行起来,调度一次。
*/
prepare_to_wait(&pool->wait, &wait, TASK_UNINTERRUPTIBLE);
mb();
/**
* 在真正调度出去前,再次判断一下curr_nr,是否有其他进程在开中断后释放了元素。
* 注意前面调用了mb()
*/
if (!pool->curr_nr)
io_schedule();
finish_wait(&pool->wait, &wait);
goto repeat_alloc;
}
释放元素:
mempool回收元素。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/**
* 释放一个元素到内存池。
*/
void mempool_free(void *element, mempool_t *pool)
{
unsigned long flags;
mb();
/**
* 如果内存池未满,就将元素加入到内存池。
*/
if (pool->curr_nr < pool->min_nr) {
spin_lock_irqsave(&pool->lock, flags);
if (pool->curr_nr < pool->min_nr) {
add_element(pool, element);
spin_unlock_irqrestore(&pool->lock, flags);
wake_up(&pool->wait);
return;
}
spin_unlock_irqrestore(&pool->lock, flags);
}
/**
* 否则释放到基本内存分配器中。
*/
pool->free(element, pool->pool_data);
}