Linux内核学习——内存管理之页框管理
Linux内存管理非常复杂,从物理内存的分门别类,到内核用户态进程的索取,可以说是包罗万象。这一篇学习页框管理机制的设计以及透过源码了解一些技术细节。
Linux内存管理——页框管理
在“内存寻址”一节中,我们知道了描述一个物理页的单位叫页框(page frame)。页框的尺寸大小和硬件和Linux系统配置有关。对Intel来说,Linux采用4KB页框尺寸作为标准内存分配单元。
- 开启PAE的情况下,为2MB。
- 如果开启了大页,那么页框尺寸为4MB。
页框之所以选择4KB大小,ULK给出了两方面原因:
- 分页系统造成的缺页异常很好解释,要么是页存在但process不被允许访问,要么是页不存在。如果不存在,内存分配器需要找一个free 4KB页框给process。(这样一来管理虚拟地址空间的分页系统的4KB单位与页框大小一致,处理起来也就省事。此外,关于缺页异常实际上也没这里描摹的那么简单,ULK这里的说法是高度抽象的。)
- 尽管4K和4M都是磁盘块尺寸的倍数,但内存和磁盘间往往传递小块更为的高效。(这是考虑到页的换入换出机制,磁盘IO比内存寻址慢的多,页越大那么单次执行换页操作就越耗时,这不难理解。)
物理内存可以分成静态+动态两部分,其中静态部分永久保留,用于硬件和Linux内核代码/静态数据结构。动态内存部分则是Linux系统RT所使用和管理。
物理内存的动静态布局大致如此:

内存模型
动态内存是如何管理的呢?这将牵扯到各个层面的管理模块,每个模块都足够复杂。在探索之前,我们先来搞清楚Linux在设计上如何抽象动态内存。
平坦模式
所谓平坦模式,是指物理地址空间连续没有空洞。这是最为理想化的模型,管理也简单。虚拟地址空间位于线性映射区域的页与物理地址空间的页帧一一对应,利用内核的某种映射机制来相互转换。
非连续模式
cpu访问物理内存,地址空间往往有着空洞。这种模式本质上是平坦模式的扩展,它相当于用空洞做间隔,把物理内存拆分成多个平坦空间,而虚拟地址空间就多了一个索引转换层,每个内存页需要去索引属于哪一块物理内存区。
为什么设计上要自找麻烦呢?用平坦模式不好吗?当然是因为外因造成的,比如NUMA架构(详见下文)。
稀疏模式
这种模式就比较新潮了,是内核发展到现代所演变出来的一种模式。平坦模式是把物理页全部抽象成一片连续的地址空间,所有页page都在mem_maps[]中,而因为NUMA架构,物理内存空间不再连续,原本的单一mem_maps[]变成了mem_maps[][],多了一个维度来索引某一块物理连续内存空间。而稀疏模式则在此基础上,引入了section的概念,每个section内部内存连续,而mem_map的page数组依附于section而不再依附于node(struct pglist_data)。
由于我们分析2.6.x内核,所以只会涉及到平坦和非连续模式,着重探索平坦模式,NUMA架构只是做一些介绍。
物理内存的三个层次
宏观上的设计大抵如此,但如果不了解微观上的各相关结构意义与耦合关系,读内核代码势必云里雾里。物理内存的管理上,有三个最为基础的数据结构:struct page,
struct pg_data_t和struct zone 。
page
内核记录了每个页框的状态:属于哪个进程;属于内核代码或数据结构;空闲等等。页框的状态保存在页描述符,其类型为struct page。内核把所有的页描述符都存在全局mem_map数组(通常存放在ZONE_NORMAL首部)。page是最为基本的存储单元,可以看成是字节数组,标准大小为4KB。
1 | |
每个页框都有一个page描述符,内部的各个字段与耦合的各个模块有关,比如buddy system,lru pageout链等。另外也可以看出内核设计上对空间的取用近乎苛刻,虽然不似WRK中充斥着大量的union语法(较新的内核4.x版本已经用union重写了,为了增强可读性),但同一个成员在不同的场景下其代表意义不同,并非单一职责。
此外,在Linux内核中,有个非常重要的全局指针变量mem_map:
1 | |
实际上是个flexible数组。
flags字段非常重要,取值非常多且意义深远:
1 | |
参考ULK的释义: 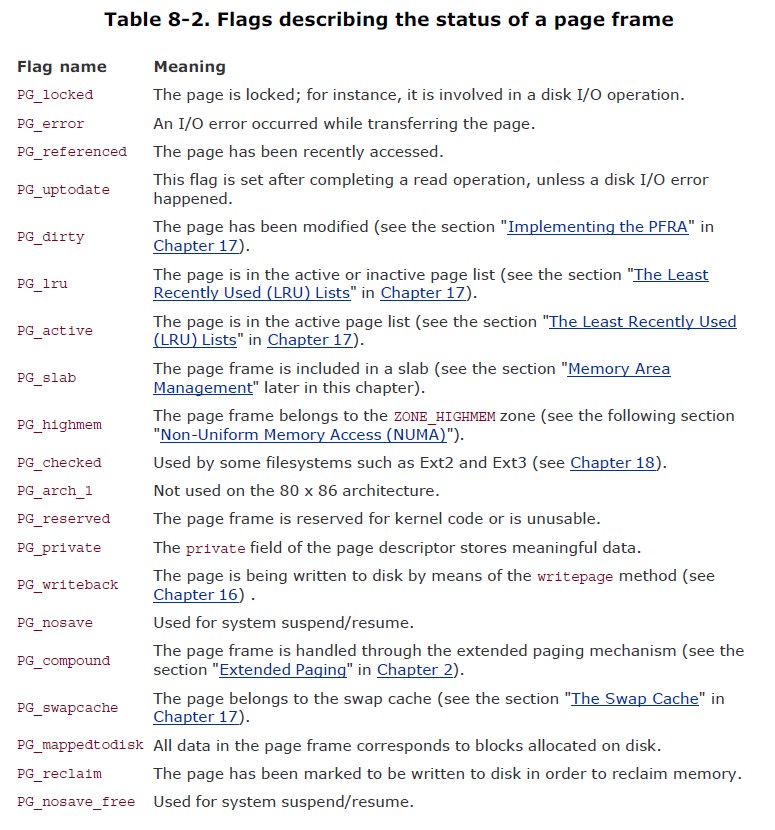
flags包含了各个耦合模块上相对的意义,设计上也可以看得出来其枚举值是可以叠加而不交叉的。关于它们的意义,具体读到相关代码时再做阐述。
node
如果所有内存都是均质的,那么物理地址整个都是平坦的,一气呵成也就不需要进行分类,但现实中往往不是所有的内存都是均质的,不同架构寻址内存的不同空间速度是不同的(Alpha,mips,etc.)。所以内存的使用布局就很有讲究,2.6支持NUMA,物理内存被瓜分成多个nodes。不同的node中的page同一CPU访问速度是相同的。所以一个node就表示一种物理内存。
1 | |
每个node又可以分成多个zones,每个node有个类型为pg_data_t的描述符,所有node描述符都存储在单一链,第一个元素由pgdat_list变量所指向。
1 | |
对于x86这种不支持NUMA的架构,node实际上只有一个,它在全局数组变量contig_page_data中:
1 | |
此外,mem_map在node_alloc_mem_map中被赋值,指向了contig_page_data.node_mem_map。
1 | |
NUMA架构比UMA架构复杂得多,整个系统的内存由node_data这个pg_data_t数组管理,而UMA只有一个简单的contig_page_data。
可以用NODE_DATA(node_id)来查找编号为node_id的节点,对于UMA架构,node只有一个,所以该宏总是返回全局的contig_page_data。
本文只讨论UMA架构,在UMA系统中, 内存就相当于一个只使用一个NUMA节点来管理整个系统的内存。而内存管理的其他地方则认为他们就是在处理一个(伪)NUMA系统。
zone
理想架构中,页框作为内存存储单元可以存储内核和用户数据,磁盘数据缓存等等。任何页数据都可以存在任何页框中,没有任何限制。然而真实的架构有着硬件限制。
Linux内核必须处理80x86架构的两个硬件限制: 1. 旧ISA总线的DMA处理器有一个严格的限制:它们只能寻址RAM的前16MB空间。 2. 现代32位计算机有很多RAM,CPU不能直接访问所有的物理内存,因为线性地址空间太小了。(内核线性地址只有3G到4G这1GB,而RAM当前比这大得多,设计成一对一肯定是不行的,所以映射机制是个复杂的大杂烩。)
为了应付这两个限制,Linux在80x86 UMA架构中分割物理内存node成3个zones。 - ZONE_DMA - 包含低16MB的内存页框,用于兼容旧ISA总线DMA处理器 - ZONE_NORMAL - 包含16MB到896MB的内存页框 - ZONE_HIGHMEM - 包含高于896MB的内存页框
ZONE_DMA给旧ISA总线设备用。ZONE_DMA和ZONE_NORMAL包含内存的常规页框,通过线性映射到4GB的线性地址空间,它们可以被内核直接使用。ZONE_HIGHMEM包含不能够直接访问的内存页框。此外,因为x64虚拟地址空间的膨胀,ZONE_HIGHMEN zone在64bit机器上总是空的(没有存在的必要)。
不同的硬件架构node分成的zone类别也有所不同,但大体上来讲都有两个非常重要的zone,一个是直接线性映射的NORMAL区,比如x86上的16M到896M这一部分偏移量的物理内存可以直接映射到3G+16M到3G+896M的虚拟线性地址上。而HIGHMEM则比较复杂,它被各种机制安排到剩余的128MB(1024MB-896MB)(不同架构可能不一样)线性空间上(也就是靠近4G的最后128MB),这些机制我们过后再探索。
1 | |
由于
struct zone结构经常被访问到, 因此这个数据结构要求以L1 Cache对齐. 另外, 这里的ZONE_PADDING( )让zone->lock和zone_lru_lock这两个很热门的锁可以分布在不同的Cahe Line中. 一个内存node节点最多也就几个zone, 因此zone数据结构不需要像struct page一样关心数据结构的大小, 因此这里的ZONE_PADDING( )可以理解为用空间换取时间(性能). 在内存管理开发过程中, 内核开发者逐渐发现有一些自选锁竞争会非常厉害, 很难获取. 像zone->lock和zone->lru_lock这两个锁有时需要同时获取锁. 因此保证他们使用不同的Cache Line是内核常用的一种优化技巧.
回过头看page,page中有到node和zone的链接,为了省空间,并没有设定单独的指针指向,而是编码成索引放在flags字段的高位(2.4.18前,page是有个指向zone的指针的,但page那么多,每个都浪费一个指针大小,浪费的内存还是相当可观的,对于linux这种性能癖,当然优化掉了)。源码中可以看到flags的标志数目是有限的,flags字段的高位可以用于编码特定node和zone号(对32位非NUMA,zone索引2位,node索引1位。(因为zone有3个而node只有1个))。
page_zone()接收一个page地址作为参数,读取flags中的最高位,通过查看zone_table来确定zone的地址:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23/**
* 接收一个页描述符的地址作为它的参数,它读取页描述符的flags字段的高位,并通过zone_table数组来确定相应管理区描述符的地址
*/
static inline struct zone *page_zone(struct page *page)
{
return zone_table[page->flags >> NODEZONE_SHIFT];
}
#define NODEZONE_SHIFT (sizeof(page_flags_t)*8 - MAX_NODES_SHIFT - MAX_ZONES_SHIFT)
/* There are currently 3 zones: DMA, Normal & Highmem, thus we need 2 bits */
#define MAX_ZONES_SHIFT 2
#ifndef CONFIG_DISCONTIGMEM
extern struct pglist_data contig_page_data;
#define NODE_DATA(nid) (&contig_page_data)
#define NODE_MEM_MAP(nid) mem_map
#define MAX_NODES_SHIFT 1
#define pfn_to_nid(pfn) (0)
#else /* CONFIG_DISCONTIGMEM */
//只关心non-NUMAzonelist数组指明首选的zone:
1
2
3
4
5
6
7
8
9
10
11
12
13
14/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* Right now a zonelist takes up less than a cacheline. We never
* modify it apart from boot-up, and only a few indices are used,
* so despite the zonelist table being relatively big, the cache
* footprint of this construct is very small.
*/
struct zonelist {
struct zone *zones[MAX_NUMNODES * MAX_NR_ZONES + 1]; // NULL delimited
};
可以看到zonelist不过是zone的一个集成,聚合了所有node的所有zone,它的内部究竟如何布局,具体分配时又如何使用等到阅读内存分配代码时再一探究竟。
保留的页框池
一方面内存有时会不够用,一些操作会被阻塞到有其他内存free。另一方面内核的某些操作是非常不想阻塞的,所以折中的办法就是留一个保留区。保留内存的数量由min_free_kbytes决定,单位为KB。这个值可以动态修改,通过sysctl系统调用或者直接写/proc文件系统下的内核变量。
1
2
3
4
5
6
7/**
* 内核保留内存池大小。
* 一般等于sqrt(16*内核直接映射内存大小)
* 但是不能小于128也不能大于65536
* 管理员可以通过写入/proc/sys/vm/min_free_kbytes来改变这个值。
*/
int min_free_kbytes = 1024;
zone的pages_min存储管理区内保留页框的数目。连同pages_low,pages_high在页框回收算法中会用到。
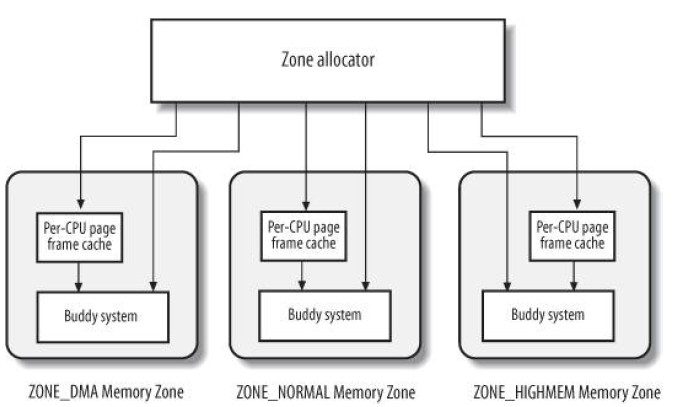
Zoned Page Frame分配器
zoned page frame分配器是一个内核子系统,处理一组连续的页框分配请求。
概要: 分配器接收分配和释放请求。分配时,组件搜索包含连续page frames的zone来满足请求。在每个zone内,page frames由组件"buddy system"控制。为了得到更高的性能,少量的page frames放在缓存中以满足多次对单个页面的分配请求。
分配接口
分配页框可以使用6个不同的函数和宏,直接对照源码最易理解。
note:以下源码取非NUMA配置。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66/**
* 分配2^order个连续的页框。它返回第一个所分配页框描述符的地址或者返回NULL
*/
#define alloc_pages(gfp_mask, order) \
alloc_pages_node(numa_node_id(), gfp_mask, order)
/**
* 用于获得一个单独页框的宏
* 它返回所分配页框描述符的地址,如果失败,则返回NULL
*/
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
/* 可以看出alloc_page就是alloc_pages的特例 */
/**
* 类似于alloc_pages,但是它返回第一个所分配页的线性地址。
*/
fastcall unsigned long __get_free_pages(unsigned int gfp_mask, unsigned int order)
{
struct page * page;
page = alloc_pages(gfp_mask, order);
if (!page)
return 0;
// 实际上是page->virtual
return (unsigned long) page_address(page);
}
/* 可以看到__get_free_pages内部也是调用了alloc_pages,只是返回的page由page_address转成了线性地址 */
/**
* 用于获得一个单独页框的宏。
*/
#define __get_free_page(gfp_mask) \
__get_free_pages((gfp_mask),0)
/* __get_free_page亦是__get_free_pages的特例 */
/**
* 用于获取填满0的页框。
* 返回的是页框对应的虚拟地址VA
*/
fastcall unsigned long get_zeroed_page(unsigned int gfp_mask)
{
struct page * page;
/*
* get_zeroed_page() returns a 32-bit address, which cannot represent
* a highmem page
*/
BUG_ON(gfp_mask & __GFP_HIGHMEM);
page = alloc_pages(gfp_mask | __GFP_ZERO, 0);
if (page)
return (unsigned long) page_address(page);
return 0;
}
/* 显然也是alloc_pages的特例,给定了__GFP_ZERO标志 */
/**
* 用于获得适用于dma的页框。
*/
#define __get_dma_pages(gfp_mask, order) \
__get_free_pages((gfp_mask) | GFP_DMA,(order))
/* 又是个特例,给定了GFP_DMA标志 */
可以看出这一族alloc函数都是对alloc_pages的包装,做了些善后工作,传递了不同的参数。
所以最后的谜底就在于alloc_pages中的alloc_pages_node函数:
1 | |
alloc_pages_node只是做心智健全检查,实际工作交给了__alloc_pages,注意参数中zonelist是通过NODE_DATA(nid)取出。
1 | |
转去看看__alloc_pages这个内存区PF分配器的总入口函数:
1 | |
可以看到整个zone的扫描策略非常复杂,但无论哪种情形,一旦满足了分配水位需求,就会调用
buffered_rmqueue函数:
1 | |
除了每CPU页框高速缓存的分配以外,重点就是__rmqueue这个函数,该函数实际上就是通往伙伴系统的分配接口。另一方面,每CPU页框高速缓存在分配时也会检查当前预存量的水位,如果不足也会调用相应的到伙伴系统的接口去批量申请页框。
关于伙伴系统的__rmqueue,我们过后再深入分析。
####Appendix
gfp_maskflags:
1 | |
###释放接口
再看释放:
1 | |
所以还是看__free_pages,对于order为0的情况,最终cold参数为0进入free_hot_cold_page中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47void fastcall free_hot_page(struct page *page)
{
// cold为0,表示是热高速缓存
free_hot_cold_page(page, 0);
}
/**
* 释放单个页框到页框高速缓存。
* page-要释放的页框描述符地址。
* cold-释放到热高速缓存还是冷高速缓存中
*/
static void fastcall free_hot_cold_page(struct page *page, int cold)
{
/**
* page_zone从page->flag中,获得page所在的内存管理区描述符。
*/
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
unsigned long flags;
arch_free_page(page, 0);
kernel_map_pages(page, 1, 0);
inc_page_state(pgfree);
if (PageAnon(page))
page->mapping = NULL;
free_pages_check(__FUNCTION__, page);
/**
* 冷高速缓存还是热高速缓存??
*/
pcp = &zone->pageset[get_cpu()].pcp[cold];
local_irq_save(flags);
/**
* 如果缓存的页框太多,就清除一些。
* 调用free_pages_bulk将这些页框释放给伙伴系统。
* 当然,需要更新一下count计数。
*/
if (pcp->count >= pcp->high)
pcp->count -= free_pages_bulk(zone, pcp->batch, &pcp->list, 0);
/**
* 将释放的页框加到高速缓存链表上。并增加count字段。
*/
list_add(&page->lru, &pcp->list);
pcp->count++;
local_irq_restore(flags);
put_cpu();
}free_pages_bulk,这涉及到伙伴系统的策略,过后再研究。
到这里,透过代码也就不难看出,每CPU页框高速缓存的管理类似zone,也有自己的阈值,判断水位高低的策略,这与zone分配器的扫描策略十分相似。
更多详细可以展开每CPU页框高速缓存的结构体与内部函数,这里限于篇幅不展开了。
对于order不为0的,核心也是free_page_bulk,说白了还是释放给伙伴系统:
1 | |
Appendix
virt_to_page:
1 | |
ZONE_HIGHMEM内核映射
high_memory变量存放HIGHMEM起始地址,设置为896M。896MB边界以上的page
frame无法直接映射在内核线性地址空间,因此内核无法直接访问。因此,__get_free_pages等函数对此情形并不适用(32位的系统中,因为__get_free_pages()无法返回一个不存在的线性地址(会溢出0xFFFFFFFF)转而返回NULL,会造成page
frame的丢失)。
为了32位系统内核可以使用HIGHMEM,做了一种映射的机制。约定如下: 1.
只用alloc_pages,alloc_page分配HIGHMEM的内存页框,虽然线性地址不存在,但是页描述符page的线性地址存在,这个东西在一开始就分配到NON-HIGHMEM区了。
2.
内核线性地址空间的最后128MB的一部分用于映射HIGHMEM的页框。线性地址对页框是一对多的,映射是暂时性的(如果都是永久的,那肯定不够用)。
当内核想访问高于896M的物理地址内存时,会从0xF8000000~0xFFFFFFFF空间范围内找一段相应大小空闲的地址空间,暂借一会儿,用毕归还。这就相当于坑位就那么多,大家轮着用。
内核有3种机制映射高端内存的页框:永久内核映射、临时内核映射和非连续内存分配。目前只关心前两种。
实际上896M只是个上限值,不一定真的会分配这么多给NORMAL,毕竟有时候物理内存没有这么大,这个值会根据真实物理内存大小动态计算出来。
内核1GB线性地址空间划分如图:
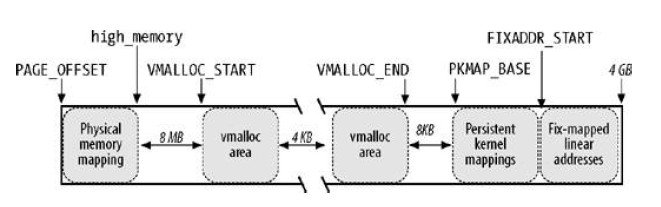
- PAGE_OFFSET ~ high_memory: 16~896MB直接映射
- VMALLOC_START ~ VMALLOC_END: 非连续内存分配
- KMAP_BASE ~ FIXADDR_START: 永久内核映射
- FIXADDR_START ~ 4GB:固定映射线性地址空间(FIX_KMAP区域为临时内核映射)
永久内核映射
在2.6内核上, 这个地址范围是4G-8M到4G-4M之间.
这个空间起叫”内核永久映射空间”或者”永久内核映射空间”,
这个空间和其它空间使用同样的页目录表,对于内核来说,就是
swapper_pg_dir,对普通进程来说,通过 CR3
寄存器指向。通常情况下,这个空间是 4M
大小,因此仅仅需要一个页表即可,内核通过来 pkmap_page_table
寻找这个页表。通过 kmap(),可以把一个 page
映射到这个空间来。由于这个空间是 4M 大小,最多能同时映射1024 个
page。因此,对于不使用的的
page,及应该时从这个空间释放掉(也就是解除映射关系),通过kunmap(),可以把一个
page 对应的线性地址从这个空间释放出来。
1 | |
映射起始地址从PKMAP_BASE开始: 1
2
3
4/**
* 永久内核映射的线性地址起始处。
*/
#define PKMAP_BASE ( (FIXADDR_BOOT_START - PAGE_SIZE*(LAST_PKMAP + 1)) & PMD_MASK )
内核使用page_address_htable散列表记录高端内存页框和线性地址的关系:
1
2
3
4
5
6
7/**
* 本散列表记录了高端内存页框与永久内核映射映射包含的线性地址。
*/
static struct page_address_slot {
struct list_head lh; /* List of page_address_maps */
spinlock_t lock; /* Protect this bucket's list */
} ____cacheline_aligned_in_smp page_address_htable[1<<PA_HASH_ORDER];page_address_map:
1
2
3
4
5
6
7
8/*
* Describes one page->virtual association
*/
struct page_address_map {
struct page *page;
void *virtual;
struct list_head list;
};
####Appendix
page_address函数:
1 | |
kmap/kunmap: 一目了然的设计 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243/**
* 建立永久内核映射。
*/
void *kmap(struct page *page)
{
/**
* kmap是允许睡眠的,意思是说不能在中断和可延迟函数中调用。
* 如果试图在中断中调用,那么might_sleep会触发异常。
*/
might_sleep();
/**
* 如果页框不属于高端内存,则调用page_address直接返回线性地址。
*/
if (!PageHighMem(page))
return page_address(page);
/**
* 否则调用kmap_high真正建立永久内核映射。
*/
return kmap_high(page);
}
/**
* 为高端内存建立永久内核映射。
*/
void fastcall *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*
* We cannot call this from interrupts, as it may block
*/
/**
* 这个函数不会在中断中调用,也不能在中断中调用。
* 所以,在这里只需要获取自旋锁就行了。
*/
spin_lock(&kmap_lock);
/**
* page_address有检查页框是否被映射的作用。
*/
vaddr = (unsigned long)page_address(page);
/**
* 没有被映射,就调用map_new_virtual把页框的物理地址插入到pkmap_page_table的一个项中。
* 并在page_address_htable散列表中加入一个元素。
*/
if (!vaddr)
vaddr = map_new_virtual(page);
/**
* 使页框的线性地址所对应的计数器加1.
*/
pkmap_count[PKMAP_NR(vaddr)]++;
/**
* 初次映射时,map_new_virtual中会将计数置为1,上一句再加1.
* 多次映射时,计数值会再加1.
* 总之,计数值决不会小于2.
*/
if (pkmap_count[PKMAP_NR(vaddr)] < 2)
BUG();
/**
* 释放自旋锁.
*/
spin_unlock(&kmap_lock);
return (void*) vaddr;
}
/**
* 为建立永久内核映射建立初始映射.
*/
static inline unsigned long map_new_virtual(struct page *page)
{
unsigned long vaddr;
int count;
start:
count = LAST_PKMAP;
/* Find an empty entry */
/**
* 扫描pkmap_count中的所有计数器值,直到找到一个空值.
*/
for (;;) {
/**
* 从上次结束的地方开始搜索.
*/
last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;
/**
* 搜索到最后一位了.在从0开始搜索前,刷新计数为1的项.
* 当计数值为1表示页表项可用,但是对应的TLB还没有刷新.
*/
if (!last_pkmap_nr) {
flush_all_zero_pkmaps();
count = LAST_PKMAP;
}
/**
* 找到计数为0的页表项,表示该页空闲且可用.
*/
if (!pkmap_count[last_pkmap_nr])
break; /* Found a usable entry */
/**
* count是允许的搜索次数.如果还允许继续搜索下一个页表项.则继续,否则表示没有空闲项,退出.
*/
if (--count)
continue;
/*
* Sleep for somebody else to unmap their entries
*/
/**
* 运行到这里,表示没有找到空闲页表项.先睡眠一下.
* 等待其他线程释放页表项,然后唤醒本线程.
*/
{
DECLARE_WAITQUEUE(wait, current);
__set_current_state(TASK_UNINTERRUPTIBLE);
/**
* 将当前线程挂到pkmap_map_wait等待队列上.
*/
add_wait_queue(&pkmap_map_wait, &wait);
spin_unlock(&kmap_lock);
schedule();
remove_wait_queue(&pkmap_map_wait, &wait);
spin_lock(&kmap_lock);
/* Somebody else might have mapped it while we slept */
/**
* 在当前线程等待的过程中,其他线程可能已经将页面进行了映射.
* 检测一下,如果已经映射了,就退出.
* 注意,这里没有对kmap_lock进行解锁操作.关于kmap_lock锁的操作,需要结合kmap_high来分析.
* 总的原则是:进入本函数时保证关锁,然后在本句前面关锁,本句后面解锁.
* 在函数返回后,锁仍然是关的.则外层解锁.
* 即使在本函数中循环也是这样.
* 内核就是这么乱,看久了就习惯了.不过你目前可能必须得学着适应这种代码.
*/
if (page_address(page))
return (unsigned long)page_address(page);
/* Re-start */
goto start;
}
}
/**
* 不管何种路径运行到这里来,kmap_lock都是锁着的.
* 并且last_pkmap_nr对应的是一个空闲且可用的表项.
*/
vaddr = PKMAP_ADDR(last_pkmap_nr);
/**
* 设置页表属性,建立虚拟地址和物理地址之间的映射.
*/
set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
/**
* 1表示相应的项可用,但是TLB需要刷新.
* 但是我们这里明明建立了映射,为什么还是可用的呢,其他地方不会将占用么?
* 其实不用担心,因为返回kmap_high后,kmap_high函数会将它再加1.
*/
pkmap_count[last_pkmap_nr] = 1;
set_page_address(page, (void *)vaddr);
return vaddr;
}
/**
* 撤销先前由kmap建立的永久内核映射
*/
void kunmap(struct page *page)
{
/**
* kmap和kunmap都不允许在中断中使用。
*/
if (in_interrupt())
BUG();
/**
* 如果对应页根本就不是高端内存,当然就没有进行内核映射,也就不用调用本函数了。
*/
if (!PageHighMem(page))
return;
/**
* kunmap_high真正执行unmap过程
*/
kunmap_high(page);
}
/**
* 解除高端内存的永久内核映射
*/
void fastcall kunmap_high(struct page *page)
{
unsigned long vaddr;
unsigned long nr;
int need_wakeup;
spin_lock(&kmap_lock);
/**
* 得到物理页对应的虚拟地址。
*/
vaddr = (unsigned long)page_address(page);
/**
* vaddr会==0,可能是内存越界等严重故障了吧。
* BUG一下
*/
if (!vaddr)
BUG();
/**
* 根据虚拟地址,找到页表项在pkmap_count中的序号。
*/
nr = PKMAP_NR(vaddr);
/*
* A count must never go down to zero
* without a TLB flush!
*/
need_wakeup = 0;
switch (--pkmap_count[nr]) {
case 0:
BUG();/* 一定是逻辑错误了,多次调用了unmap */
case 1:
/*
* Avoid an unnecessary wake_up() function call.
* The common case is pkmap_count[] == 1, but
* no waiters.
* The tasks queued in the wait-queue are guarded
* by both the lock in the wait-queue-head and by
* the kmap_lock. As the kmap_lock is held here,
* no need for the wait-queue-head's lock. Simply
* test if the queue is empty.
*/
/**
* 页表项可用了。need_wakeup会唤醒等待队列上阻塞的线程。
*/
need_wakeup = waitqueue_active(&pkmap_map_wait);
}
spin_unlock(&kmap_lock);
/* do wake-up, if needed, race-free outside of the spin lock */
/**
* 有等待线程,唤醒它。
*/
if (need_wakeup)
wake_up(&pkmap_map_wait);
}
临时内核映射
内核在 FIXADDR_START 到 FIXADDR_TOP 之间保留了一些线性空间用于特殊需求。这个空间称为”固定映射空间”在这个空间中,有一部分用于高端内存的临时映射。临时内核映射可以用在中断处理程序和可延迟函数内部,它们从不阻塞当前进程。
这块空间具有如下特点:
- 每个 CPU 占用一块空间
- 在每个 CPU 占用的那块空间中,又分为多个小空间,每个小空间大小是 1 个
page,每个小空间用于一个目的,这些目的定义在 kmap_types.h 中的
km_type中。
任一页框都可以通过一个窗口映射到内核地址空间,这些窗口非常少。
每个CPU有自己的13个窗口集合: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#ifdef CONFIG_DEBUG_HIGHMEM
# define D(n) __KM_FENCE_##n ,
#else
# define D(n)
#endif
/**
* 系统为每个CPU预留了13个临时内核映射页表项。这是它们在线性地址表中的下标。
*/
enum km_type {
D(0) KM_BOUNCE_READ,
D(1) KM_SKB_SUNRPC_DATA,
D(2) KM_SKB_DATA_SOFTIRQ,
D(3) KM_USER0,
D(4) KM_USER1,
D(5) KM_BIO_SRC_IRQ,
D(6) KM_BIO_DST_IRQ,
D(7) KM_PTE0,
D(8) KM_PTE1,
D(9) KM_IRQ0,
D(10) KM_IRQ1,
D(11) KM_SOFTIRQ0,
D(12) KM_SOFTIRQ1,
D(13) KM_TYPE_NR
};
这些符号都只是线性地址的一个下标: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42enum fixed_addresses {
FIX_HOLE,
FIX_VSYSCALL,
#ifdef CONFIG_X86_LOCAL_APIC
FIX_APIC_BASE, /* local (CPU) APIC) -- required for SMP or not */
#endif
#ifdef CONFIG_X86_IO_APIC
FIX_IO_APIC_BASE_0,
FIX_IO_APIC_BASE_END = FIX_IO_APIC_BASE_0 + MAX_IO_APICS-1,
#endif
#ifdef CONFIG_X86_VISWS_APIC
FIX_CO_CPU, /* Cobalt timer */
FIX_CO_APIC, /* Cobalt APIC Redirection Table */
FIX_LI_PCIA, /* Lithium PCI Bridge A */
FIX_LI_PCIB, /* Lithium PCI Bridge B */
#endif
#ifdef CONFIG_X86_F00F_BUG
FIX_F00F_IDT, /* Virtual mapping for IDT */
#endif
#ifdef CONFIG_X86_CYCLONE_TIMER
FIX_CYCLONE_TIMER, /*cyclone timer register*/
#endif
#ifdef CONFIG_HIGHMEM
FIX_KMAP_BEGIN, /* reserved pte's for temporary kernel mappings */
FIX_KMAP_END = FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1,
#endif
#ifdef CONFIG_ACPI_BOOT
FIX_ACPI_BEGIN,
FIX_ACPI_END = FIX_ACPI_BEGIN + FIX_ACPI_PAGES - 1,
#endif
#ifdef CONFIG_PCI_MMCONFIG
FIX_PCIE_MCFG,
#endif
__end_of_permanent_fixed_addresses,
/* temporary boot-time mappings, used before ioremap() is functional */
#define NR_FIX_BTMAPS 16
FIX_BTMAP_END = __end_of_permanent_fixed_addresses,
FIX_BTMAP_BEGIN = FIX_BTMAP_END + NR_FIX_BTMAPS - 1,
FIX_WP_TEST,
__end_of_fixed_addresses
};
当要进行一次临时映射的时候,需要指定映射的目的,根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。通过
kmap_atomic()可实现临时映射:
1 | |
撤销kunmap_atomic: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34/**
* 撤销内核临时映射
*/
void kunmap_atomic(void *kvaddr, enum km_type type)
{
#ifdef CONFIG_DEBUG_HIGHMEM
unsigned long vaddr = (unsigned long) kvaddr & PAGE_MASK;
enum fixed_addresses idx = type + KM_TYPE_NR*smp_processor_id();
if (vaddr < FIXADDR_START) { // FIXME
dec_preempt_count();
preempt_check_resched();
return;
}
if (vaddr != __fix_to_virt(FIX_KMAP_BEGIN+idx))
BUG();
/*
* force other mappings to Oops if they'll try to access
* this pte without first remap it
*/
/**
* 取消映射并刷新TLB
*/
pte_clear(kmap_pte-idx);
__flush_tlb_one(vaddr);
#endif
/**
* 允许抢占,并检查调度点。
*/
dec_preempt_count();
preempt_check_resched();
}
高端内存是物理内存的概念,无论何种映射,最终它映射到的是内核线性地址空间,和用户进程没有什么关系,不要混淆。
Buddy System(伙伴系统)Algorithm
内存管理的经典问题:碎片化 两种解决方案: - 非连续空闲页框映射到连续的线性地址 - 定制一套体系处理空闲连续页框块,分配与回收
出于种种原因,Linux内核使用第二种方案(详见ULK,实际上一言以蔽之——第二种方案更契合Linux)。这个方案就是buddy system。空闲页框分组为11个双向循环链表,每个链表存储大小为1,2,4,8,16,32,64,128,256,512,1024个连续的页框,形成块。每个块的第一个页框的首地址都是该块大小的整数倍。
涉及的数据结构主要是两个,前面提到的所有page数组mem_map以及free_area。
关于mem_map,前面初始化的代码中可以看到它是整个node的page集合。而对于每个zone的page,都是node的page也就是mem_map的子集。zone的zone_mem_map成员就是在mem_map中的起始成员。
另一方面,zone的free_area数组存储了这11个链(MAX_ORDER=11)。看一下free_area结构:
1
2
3
4struct free_area {
struct list_head free_list;
unsigned long nr_free;
};1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17struct page{
...
/**
* 可用于正在使用页的内核成分(如在缓冲页的情况下,它是一个缓冲器头指针。)
* 如果页是空闲的,则该字段由伙伴系统使用。
* 当用于伙伴系统时,如果该页是一个2^k的空闲页块的第一个页,那么它的值就是k.
* 这样,伙伴系统可以查找相邻的伙伴,以确定是否可以将空闲块合并成2^(k+1)大小的空闲块。
*/
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache
* When page is free, this indicates
* order in the buddy system.
*/
...
};
alloc
__rmqueue()负责在zone中找空闲块,顺着上次看到的__alloc_pages看下去,__alloc_pages()=>buffered_rmqueue()=>__rmqueue():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49/**
* 在管理区中找到一个空闲块。
* 它需要两个参数:管理区描述符的地址和order。Order表示请求的空闲页块大小的对数值。
* 如果页框被成功分配,则返回第一个被分配的页框的页描述符。否则返回NULL。
* 本函数假设调用者已经禁止和本地中断并获得了自旋锁。
*/
static struct page *__rmqueue(struct zone *zone, unsigned int order)
{
struct free_area * area;
unsigned int current_order;
struct page *page;
/**
* 从所请求的order开始,扫描每个可用块链表进行循环搜索。
*/
for (current_order = order; current_order < MAX_ORDER; ++current_order) {
area = zone->free_area + current_order;
/**
* 对应的空闲块链表为空,在更大的空闲块链表中进行循环搜索。
*/
if (list_empty(&area->free_list))
continue;
/**
* 运行到此,说明有合适的空闲块。
*/
page = list_entry(area->free_list.next, struct page, lru);
/**
* 首先在空闲块链表中删除第一个页框描述符。
*/
list_del(&page->lru);
rmv_page_order(page);
area->nr_free--;
/**
* 并减少空闲管理区的空闲页数量。
*/
zone->free_pages -= 1UL << order;
/**
* 如果2^order空闲块链表中没有合适的空闲块,那么就是从更大的空闲链表中分配的。
* 将剩余的空闲块分散到合适的链表中去。
*/
return expand(zone, page, order, current_order, area);
}
/**
* 直到循环结束都没有找到合适的空闲块,就返回NULL。
*/
return NULL;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21static inline struct page *
expand(struct zone *zone, struct page *page,
int low, int high, struct free_area *area)
{
unsigned long size = 1 << high;
while (high > low) {
area--;
high--;
size >>= 1;
BUG_ON(bad_range(zone, &page[size]));
/*
* 后半部分(page[size])加入free_area->free_list中,并设定order
* 前半部分(page),继续进行分裂或者返回
*/
list_add(&page[size].lru, &area->free_list);
area->nr_free++;
set_page_order(&page[size], high);
}
return page;
}
free
释放使用__free_pages_bulk(): 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97/**
* 按照伙伴系统的策略释放页框。
* page-被释放块中所包含的第一个页框描述符的地址。
* zone-管理区描述符的地址。
* order-块大小的对数。
* base-纯粹由于效率的原因而引入。其实可以从其他三个参数计算得出。
* 该函数假定调用者已经禁止本地中断并获得了自旋锁。
*/
static inline void __free_pages_bulk (struct page *page, struct page *base,
struct zone *zone, unsigned int order)
{
/**
* page_idx包含块中第一个页框的下标。
* 这是相对于管理区中的第一个页框而言的。
*/
unsigned long page_idx;
struct page *coalesced;
/**
* order_size用于增加管理区中空闲页框的计数器。
*/
int order_size = 1 << order;
if (unlikely(order))
destroy_compound_page(page, order);
page_idx = page - base;
/**
* 大小为2^k的块,它的线性地址都是2^k * 2 ^ 12的整数倍。
* 相应的,它在管理区的偏移应该是2^k倍。
*/
BUG_ON(page_idx & (order_size - 1));
BUG_ON(bad_range(zone, page));
/**
* 增加管理区的空闲页数
*/
zone->free_pages += order_size;
/**
* 最多循环10 - order次。每次都将一个块和它的伙伴进行合并。
* 每次从最小的块开始,向上合并。
*/
while (order < MAX_ORDER-1) {
struct free_area *area;
struct page *buddy;
int buddy_idx;
/**
* 最小块的下标。它是要合并的块的伙伴。
* 注意异或操作的用法,是如何用来寻找伙伴的。
* 相当于在page_idx加上或者减去1 << order的距离就是buddy_idx
*/
buddy_idx = (page_idx ^ (1 << order));
/**
* 通过伙伴的下标找到页描述符的地址。
*/
buddy = base + buddy_idx;
if (bad_range(zone, buddy))
break;
/**
* 判断伙伴块是否是大小为order的空闲页框的第一个页。
* 首先,伙伴的第一个页必须是空闲的(_count == -1)
* 同时,必须属于动态内存(PG_reserved被清0,PG_reserved为1表示留给内核或者没有使用)
* 最后,其private字段必须是order
*/
if (!page_is_buddy(buddy, order))
break;
/**
* 运行到这里,说明伙伴块可以与当前块合并。
*/
/* Move the buddy up one level. */
/**
* 伙伴将被合并,将它从现有链表中取下。
*/
list_del(&buddy->lru);
area = zone->free_area + order;
area->nr_free--;
rmv_page_order(buddy);
/*
* 计算parent_idx
*/
page_idx &= buddy_idx;
/**
* 将合并了的块再与它的伙伴进行合并。
*/
order++;
}
/**
* 伙伴不能与当前块合并。
* 将块插入适当的链表,并以块大小的order更新第一个页框的private字段。
*/
coalesced = base + page_idx;
set_page_order(coalesced, order);
list_add(&coalesced->lru, &zone->free_area[order].free_list);
zone->free_area[order].nr_free++;
}__free_pages()=>__free_pages_ok()=>free_pages_bulk()=>__free_pages_bulk()。
CPU页框高速缓存
内核经常请求或释放单个页框(对应order=0的情况),为了提升性能,内存管理区定义了一个每CPU页框高速缓存用于包含一些预先分配的页框。我们先前在Zoned Page Frame分配器中的分配和释放操作代码中已经看过了。 Linux为每个内存管理区和每CPU提供了两个高速缓存:热高速和冷高速。两种类型针对不同的请求而设计。
zone的pageset成员保存了两个高速缓存: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* 管理区每CPU页框高速缓存描述符
*/
struct per_cpu_pageset {
/**
* 热高速缓存和冷高速缓存。
*/
struct per_cpu_pages pcp[2]; /* 0: hot. 1: cold */
} ____cacheline_aligned_in_smp;
/**
* 内存管理区页框高速缓存描述符
*/
struct per_cpu_pages {
/**
* 高速缓存中的页框个数
*/
int count; /* number of pages in the list */
/**
* 下界,低于此就需要补充高速缓存。
*/
int low; /* low watermark, refill needed */
/**
* 上界,高于此则向伙伴系统释放页框。
*/
int high; /* high watermark, emptying needed */
/**
* 当需要增加或者减少高速缓存页框时,操作的页框个数。
*/
int batch; /* chunk size for buddy add/remove */
/**
* 高速缓存中包含的页框描述符链表。
*/
struct list_head list; /* the list of pages */
};
alloc
回顾一下处理order==0时使用CPU页框高速缓存分配的场景:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105/**
* 返回第一个被分配的页框的页描述符。如果内存管理区没有所请求大小的一组连续页框,则返回NULL。
* 在指定的内存管理区中分配页框。它使用每CPU页框高速缓存来处理单一页框请求。
* zone:内存管理区描述符的地址。
* order:请求分配的内存大小的对数,0表示分配一个页框。
* gfp_flags:分配标志,如果gfp_flags中的__GFP_COLD标志被置位,那么页框应当从冷高速缓存中获取,否则应当从热高速缓存中获取(只对单一页框请求有意义。)
*/
static struct page *
buffered_rmqueue(struct zone *zone, int order, int gfp_flags)
{
unsigned long flags;
struct page *page = NULL;
int cold = !!(gfp_flags & __GFP_COLD);
/**
* 如果order!=0,则每CPU页框高速缓存就不能被使用。
*/
if (order == 0) {
struct per_cpu_pages *pcp;
/**
* 检查由__GFP_COLD标志所标识的内存管理区本地CPU高速缓存是否需要被补充。
* 其count字段小于或者等于low
*/
pcp = &zone->pageset[get_cpu()].pcp[cold];
local_irq_save(flags);
/**
* 当前缓存中的页框数低于low,需要从伙伴系统中补充页框。
* 调用rmqueue_bulk函数从伙伴系统中分配batch个单一页框
* rmqueue_bulk反复调用__rmqueue,直到缓存的页框达到low。
*/
if (pcp->count <= pcp->low)
pcp->count += rmqueue_bulk(zone, 0,
pcp->batch, &pcp->list);
/**
* 如果count为正,函数从高速缓存链表中获得一个页框。
* count减1
*/
/* 这就是分配的核心了,直接操作就行了,哪那么多__rmqueue,所以快 */
if (pcp->count) {
page = list_entry(pcp->list.next, struct page, lru);
list_del(&page->lru);
pcp->count--;
}
local_irq_restore(flags);
/**
* 没有和get_cpu配对使用呢?
* 这就是内核,外层一定调用了get_cpu。这种代码看起来头疼。
*/
put_cpu();
}
/**
* 内存请求没有得到满足,或者是因为请求跨越了几个连续页框,或者是因为被选中的页框高速缓存为空。
* 调用__rmqueue函数(因为已经保护了,直接调用__rmqueue即可)从伙伴系统中分配所请求的页框。
*/
if (page == NULL) {
spin_lock_irqsave(&zone->lock, flags);
page = __rmqueue(zone, order);
spin_unlock_irqrestore(&zone->lock, flags);
}
/**
* 如果内存请求得到满足,函数就初始化(第一个)页框的页描述符
*/
if (page != NULL) {
BUG_ON(bad_range(zone, page));
/**
* 将第一个页清除一些标志,将private字段置0,并将页框引用计数器置1。
*/
mod_page_state_zone(zone, pgalloc, 1 << order);
prep_new_page(page, order);
/**
* 如果__GFP_ZERO标志被置位,则将被分配的区域填充0。
*/
if (gfp_flags & __GFP_ZERO)
prep_zero_page(page, order, gfp_flags);
if (order && (gfp_flags & __GFP_COMP))
prep_compound_page(page, order);
}
return page;
}
//展开看补充页框的操作,实际上也是通过__rmqueue操作的,通过拿到的page->lru链到传入的pcp->list:
static int rmqueue_bulk(struct zone *zone, unsigned int order,
unsigned long count, struct list_head *list)
{
unsigned long flags;
int i;
int allocated = 0;
struct page *page;
spin_lock_irqsave(&zone->lock, flags);
for (i = 0; i < count; ++i) {
page = __rmqueue(zone, order);
if (page == NULL)
break;
allocated++;
list_add_tail(&page->lru, list);
}
spin_unlock_irqrestore(&zone->lock, flags);
return allocated;
}
free
再回顾一下free:
1 | |
暂时只关心先对于order==0的情况处理(即高速缓存):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52void fastcall free_hot_page(struct page *page)
{
free_hot_cold_page(page, 0);
}
void fastcall free_cold_page(struct page *page)
{
free_hot_cold_page(page, 1);
}
/* 这两个都是封装 */
/* core api */
/**
* 释放单个页框到页框高速缓存。
* page-要释放的页框描述符地址。
* cold-释放到热高速缓存还是冷高速缓存中
*/
static void fastcall free_hot_cold_page(struct page *page, int cold)
{
/**
* page_zone从page->flag中,获得page所在的内存管理区描述符。
*/
struct zone *zone = page_zone(page);
struct per_cpu_pages *pcp;
unsigned long flags;
arch_free_page(page, 0);
kernel_map_pages(page, 1, 0);
inc_page_state(pgfree);
if (PageAnon(page))
page->mapping = NULL;
free_pages_check(__FUNCTION__, page);
/**
* 冷高速缓存还是热高速缓存??
*/
pcp = &zone->pageset[get_cpu()].pcp[cold];
local_irq_save(flags);
/**
* 如果缓存的页框太多,就清除一些。
* 调用free_pages_bulk将这些页框释放给伙伴系统。
* 当然,需要更新一下count计数。
*/
if (pcp->count >= pcp->high)
pcp->count -= free_pages_bulk(zone, pcp->batch, &pcp->list, 0);
/**
* 将释放的页框加到高速缓存链表上。并增加count字段。
*/
list_add(&page->lru, &pcp->list);
pcp->count++;
local_irq_restore(flags);
put_cpu();
}
总结
到此,关于页框的管理策略,从zoned alloc/free system到((per CPU cache)+buddy system),一系列的算法已经了然于胸。物理内存的层层架构、支配与回收也就这么回事儿。
ULK的这张图很透彻: