格物致知(0)——系统漫游
对于想要学习编程的新人来说,当下无疑是最好的时节,编程语言发展至今,新生代的语言在诞生之初往往伴随着强大的生态附属以及友好的语法特性,这大大降低了上手门槛,使得新手也可以轻松地完成任务而不必陷于囹圄。当下也是最坏的时节,现代编程语言高高在上,屏蔽了太多细节与原理,这鸿沟天堑阻绝了新人知其所以然的机会,却又如何技进于道?本系列将以CSAPP(Computer Systems: A Programmer's Perspective,中译本为《深入理解计算机系统》)上半为蓝本,接轨当下,让我们格物致知,打通认知体系的奇经八脉。
系统漫游
众所周知,计算机系统是由硬件和软件组成的,不论是超级计算机、集群服务器,还是家用电脑、移动端设备(平板、手机)、IoT设备(如路由器、摄像头)应皆如是。硬件五花八门、各司其职,对于非特定领域开发者来说,我们只需要了解两个核心硬件:中央处理器(CPU)和内存(主存,一般称RAM)即可。
除了CPU以外,还有一种叫图形显示器(GPU)的东西,这东西在当下可是大展身手,无出其右(同学,便宜的矿卡来一块不?都是锻炼过的,GPT用了都说好)。 机械硬盘(SATA)、固态硬盘(SSD)对于一台主机来说很重要,但站在程序开发者视角来说则没那么重要。 至于显示器、鼠标、键盘等等都属于外设,如果不是为了打游戏,那么研究它们毫无意义(doge)
硬件虽然服务于软件,但硬件才是大爹。事实上,互联网的崛起、从单点到分布式,以及历年的技术革命:诸如大数据、云计算、区块链再到当前潜在商业价值巨大的GPT,之所以能够surfing在浪潮之巅,根本上都是因为硬件的迭代升级。硬件的能力突破了某个瓶颈以后(算力、造价、效率等等...),业界大能才能把此前仅限于理论可行的方案落地,开辟出当前欣欣向荣的生态大环境。
那么硬件和软件是怎么沟通的呢?不同硬件厂商繁多,标准规格大相径庭,如果将这些都暴露给软件开发者,那简直是一场噩梦。事实上在上古时代,编程就是这样一件不可思议的狠活,程序开发者需要去理解使用的硬件,对着它的规格书使用原生接口来完成自己的工作。随着软件的发展,先驱者抽象出中间层(在软件开发领域,没有什么事是一个中间层搞不定的,如果有,就再加一个中间层),让它负责对接所有硬件,开发者只需要和这个中间层打交道即可。那么这个中间层是什么呢?它的真身就是我们常常说的操作系统(OS, Operating System),操作系统实际上也经历了漫长的发展历史长河,一直到现在我们耳熟能详的Windows, Linux, Mac OS, Android, IOS等。时至今日,我们更愿意称它们为“现代操作系统”,“现代”这一限定词可谓意义非凡,它浓缩了这一路上面对重重困境披荆斩棘的解决之道,并最终沉淀成标准,任岁月打磨。
即使是家喻户晓的Windows,实际上也有着漫长的历史,严格来说,Windows不是具体的某个系统,而是一种徽章,从最古老的DOS到Windows 9x再到Windows NT,底层的变化翻天覆地,而Win 7(前身是赫赫有名的失败品Vista)之后历经Win 8、Win 10再到“内测”的Win 11,安全加固、系统生态等方方面面都愈发成熟。
如果说Windows是自立门户、自成标准,那么像Linux, Mac OS, FreeBSD, Solaris都算作类Unix系统,它们有着相当多的共同点,比如遵守POSIX标准,集成了GNU套件。
操作系统实际上也是软件,事实上,它就是我们开机以后第一个运行的体量最大的软件,OS提供了其他软件运行的土壤。现代操作系统整体分为两大部分:内核(kernel)和外壳(shell),内核负责决策、调度和资源管理,里面住着的都是一等公民(常驻的内核代码:进程管理、内存管理、文件设备I/O、中断),外壳则面向开发者与用户进行交互:你只能通过使用我开放的接口、组合成你想实现的功能。通过这些接口(即系统API)我们可以编写各种程序,进而完成各种各样的软件,只不过受制于人(你得看具体OS厂商的脸色),能做的事儿有限。

你可能会问:为啥现代操作系统要分层呢?大家写的程序都和OS内核平起平坐,功能岂不是更丰富?嗯,上古时期DOS就是这么干的,所以那个年代病毒满天飞,挡都挡不住。
因此,在现代操作系统中,生态环境被分成了两部分:内核态与用户态。
- 与硬件打交道的代码通通运行在内核层,各类硬件设备分门别类一般有着业界统一标准或是自定义标准,OS通过设备驱动来与它们交互,它们以插件的形式,或先天集成在OS内核里,或后天装载插入;
- 我们日常所用的大部分软件,诸如chrome浏览器、QQ音乐、Steam等它们之中的大部分工作在用户态;
- 像是一些防护软件比如火绒、360、QQ电脑管家等则兼具用户与内核态,为什么说是兼具呢?因为用户态有功能局限性,防护软件要和那些无孔不入的恶意程序对抗,那势必要下沉到内核去获取更高的权限与更强大的power。实际上,操作系统并不仅仅提供用户态的接口,内核层往往也会提供,而除了少量做设备驱动和二进制安全研究的人士,大部分开发者是用不到它们的。
内核态与用户态是现代操作系统的概念,在很多上下文中会等价于Ring 0/3态,后者是站在CPU的视角来看的,虽然二者有一定区别,但基本绑定。
在我尚未学习内核/驱动编程的时候,总觉着写内核态程序的高人一等,直到上下求索、建立一定的知识体系后才明白:写程序就是写程序,本没有什么优劣,不过是所在的层与生态环境不同罢了。
操作系统作为中间层,其常驻的内核代码会控制CPU与内存的调度与分配,我们知道程序无非就是代码 + 数据(代码其实也是数据,嗯,这就是二进制安全的关键),每一行代码的执行都由CPU来完成,而数据则放置于内存。对于CPU来说,各厂商的指令集迥然不同,在CPU的世界里,一切都是二进制的,它的眼里只有0和1,对于一连串的0101...0011,不同厂商对他们进行了特有的定义,比如通过规定指令集定长,其中1100表示功能A、0011表示功能B、1010表示功能C等等。那么,按照这样的设计,当我们使用不同的CPU编写程序(包括编写操作系统)时,就需要去对着厂商的手册,一点一点手码0101吗?啊,这。。。
当下显然不会,这就要说起编程语言的发展历程了~
编程语言简史
机器语言
CPU按架构会有自己的指令集,它们的背后也确实就是0101,只不过厂商赋予了语义并在硬件上实现了相应的功能。上古时期的编程确实就是直接写0101(这个时候的CPU还称不上是CPU)来完成的,彼时我们称其为机器语言,显然,机器语言对机器绝对友好,但对程序员绝对不友好,它的缺点肉眼可见:难记难改难纠错、费时费力费树脂(卧槽,原!)。痛,太痛了!
世界上的第一个程序媛叫Ada,头像参考二进制安全必备神器:IDA Pro~
业界把机器语言称为“第一代计算机语言”。
汇编语言
为了克服机器语言不说人话的问题,大佬们给CPU聘请了翻译(诶,您给翻译翻译什么叫0101?什么他么的叫0101?什么他么的叫他么的0101?),而这就产生了第二代计算机语言:汇编语言。简单来说,汇编语言就是将机器码翻译成与实际意义相关的英文
+
数字缩写助记符(所以汇编指令也叫机器码助记符),比如mov eax, 3表示把数值3赋值给寄存器eax(至于什么是寄存器,这个学到的时候再说)。汇编语言的好处就在于相比于机器语言,编写起来没那么男的女的折磨,我们先用汇编助记符来编写程序,编写完成后经过翻译再变成机器码给到CPU去执行,而这个负责翻译的模块则被称作:汇编器。
汇编语言是一种低级语言(这里的低级不含贬义,只是说它所在的层级较低,与底层更近),它和具体的CPU指令集绑定,因此并不通用,尽管相对机器语言书写上舒服了很多,但编写门槛依然较高无法让人满意。
高级语言
还记得前面讲操作系统时我们曾遇到的困境吗?不只是CPU,其他硬件的不同厂商标准规格都可能千差万别,如果需要开发者每一个都掌握,那属实 crazy。这一点对于编程语言来说也一样,既然汇编难用又不通用,我们何不再架上一层中间层,搞一个统一的语言出来,再多安排几个翻译员,每个人专门负责从统一语言到某一个特定汇编语言的翻译工作。通过这一中间层的屏蔽,开发者只需要掌握这门统一语言即可编写在任何CPU指令集上运行的程序,而无需了解特定的指令集。(你看,我就说没什么困难是一个中间层搞不定的吧~)而且,在设计上我们也可以让这门统一语言尽量说人话,从而降低编写的难度与维护的成本。
而这,其实就是第三代编程语言:高级语言的由来。只不过,在漫长的历史长河中,有太多大能都达成了此共识,其结果就是高级编程语言如雨后春笋般,甚至直到2023的现在还在源源不断的涌现,从古早的BASIC、PASCAL、C、FORTRAN到现在的Go、Rust,它们都是高级编程语言,随着时代的进步,其中难免有一些被环境所淘汰,但也有一些历久弥新,每个不同的高级语言都蕴含了作者独特的审美与对环境生态、软件开发的理解,伴随着社区、使用群体的发展各自开宗立派、培养着自家忠实的拥趸。
高级语言在设计上大体分为两派:编译型和解释型。前者(比如C、C++)主张对编写的源代码进行前置处理:通过一种叫“编译”的方式把它变成汇编语言,再由汇编器变成机器码,最终在机器上执行,它的核心要点在于:所有代码在一开始就要全部翻译成最终的机器码,运行时直接执行;而后者(比如Ruby,Python、Javascript)则主张后置处理:在运行时通过解释器来一步一步地、当我执行到具体的某一行时,让同声传译把它变成机器码执行,每说一句就翻译一句原地执行。显然,前者把一些重活放在了编译期,得到的好处就是运行时更快,但后者则因为实时处理的模式往往在语法上可以更加灵活。而在高级语言发展过程中,这两派逐渐水乳交融、佛道双修,比如像Java、C#,它们都是半编译、半解释型,再像是Javascript、Python这种一开始做成解释型的,为了能够针对热点代码提速或是公共代码复用,也陆续引入了JIT、预编译的能力。
总之,高级语言在设计上与自然语言(英语)更接近(可别跟我提易语言,真不熟……),而与硬件功能相分离,便于开发者掌控而屏蔽底层差异。高级语言的优点在于:通用性强、兼容性好、便于移植,但同样的,天下没有免费的晚餐,相比直接写汇编来说其生成的代码更加臃肿,性能上也有所差距。因此像操作系统这种对性能要求苛刻的程序会经常在高级语言里内联汇编代码(通俗理解就是:高级语言的局部嵌入汇编代码,这需要高级语言的支持)来提速。
但另一方面,在2023的今天,现代编译器已今非昔比可谓十分强大,在现代的一些架构上已然抹平甚至超越了使用汇编语言来编写的程序性能(编译器比我聪明系列)。
缘起"Hello, world"
“Hello, world”之于编程,就好比“衬衫的价格是”之于英语听力。不管你是何门何派、哪个语种,入门的第一站都是"Hello, world",经久不衰。这一切,都要从此说起:我们意兴盎然的选择了某门语言,开始修炼本门功法,不同门派的功法各有千秋:有些功法小巧精妙(C),有些功法直捣黄龙(go),有些功法艰深晦涩(C++),有些功法必先自宫(Rust),有些功法大开大阖(Java),有些功法乱七八糟(你猜我说的是谁?)。
然而不管我们选择了哪一派,从它变成母语的那一天开始,我们就被深深地打上了相应的烙印。尽管在修炼过程中我们能够解决越来越多的问题,但与此同时它所植入的灵魂烙印也把我们的解题思维牢牢限制在本家系统之内。直到皇天不负有心人,本家功夫大成,我们得以窥探别门别派的心法口诀,坐而悟道。而本门功夫,修炼周期各有长短,这期间一旦受其他门派影响,轻则自我怀疑,重则道心破碎。
有些选择了C语言的小伙伴,学了一年也不会做任何酷炫的app,只会在黑框框里跑四则运算,看到邻家8岁的小男孩都用python写AI画图了,顿时道心破碎,弃C如敝履。
我们现在分别使用C、Java和Python来写一个Hello, world:
1 | |
1 | |
1 | |
嗯,按照各家功法所述,我们应该分别保存成hello.c, hello.java, hello.py。还记得功法让我们怎么称呼它们吗?对,源文件!这些文件里的内容就是源代码,它们都是文本文件。那么源文件怎么执行起来输出“Hello, world”呢?这个时候,各家功法就有所分歧了.
C
C是一门编译型语言,使用C语言编写的hello.c需要经过预处理器、编译器、汇编器、链接器来一步一步处理,最终生成二进制可执行文件,不同平台都制定了可执行文件组织结构的标准,比如在Windows里叫PE(Portable Executable),像是我们平时双击的xxx.exe就是典型的PE可执行文件(实际上.sys, .dll也都是PE,前者是内核态所运行的驱动程序、后者是用于共享的动态链接库),而在大部分类Unix系统里用ELF(Executable and Linking Format)),它们往往没有后缀名。实际上后缀名只是一种浮于表面的印记,通过盖戳的方式让人类更容易分辨它是一个什么文件,真正决定文件制式的是它的内容信息,图片、视频、文本、可执行文件,他们各有各的标准结构。
既然后缀名只是印记,那岂不是可以用来诱骗?早年的恶意软件、病毒可不就是充分利用了此种手段,整个Windows乌烟瘴气。用户也可以利用这一小手段:比如我上小学的时候,隐藏文件早就不用系统提供的方法了,我会把他的后缀改成其他资源的类型,诶嘿,你打不开了吧!后来到了中学,懂得套路又多了一些,这次就直接打开二进制编辑器,偷偷改掉某某视频的文件头~
Mac OS逼格比较高,它的可执行文件格式叫Mach-O(Mach Object File Format),是一种类似ELF的制式,iOS也是这套。
也就是说,我们的源代码经过了重重流水线关卡,最终变成可执行文件。现在我来问你,这每道关卡都在折腾啥?相信这个问题应该难不倒有一年以上C编程经验的同学,毕竟C派重视基础,门徒大都喜欢刨根问底。

一言以蔽之:预处理器负责展开头文件、处理宏;编译器负责将加工后的源文件翻译成汇编语言源代码;汇编器再将汇编语言转化成机器码、生成可重定向的目标程序;最终由链接器整合所有目标程序,按照可执行文件的制式整合成可执行文件。整个过程说起来简单,但其实每一步展开都是宏篇巨幅。作为编程导论,我们暂不去深入了解每一步都是怎么做的,我们的疑问是:为什么需要这几步?如果上面的内容你有认真看过并思考过,那么这个问题的答案是显而易见的:我们需要在设计上分层,每一层各司其职,邻层相濡、隔层相忘。上图的中间部分,从C源代码编译成汇编、再从汇编到机器码这一过程相信通过上文你已经十分理解了,那么剩下的头尾各有什么作用呢?
先说头部的预处理器:预处理器这一步实际上是C语言特有的,它在设计上有一个头文件和源文件的区分,头文件做公开声明,源文件做内隐实现,你在写代码的时候可以引用别人的代码库,比如hello.c中的printf函数,它在前面通过#include宏引入的stdio.h中声明,作用就是在标准输出按照C-format制式打印字符串。此外,C语言还支持一种被称为宏(macro)的强大功能(宏和指针可谓是C的两大神器,一旦掌握了这两个东西,写起C来可谓运斤成风),宏代码的替换也是在预处理器中完成的,而具体怎么操作,等我们深入学习C语言时再做展开。
再说尾部的链接器:实际上我们生成的hello.o只包含了在hello.c中书写的单个文件的那部分代码,而对于整个工程项目来说,我们可能会写出一大堆源文件,且除了自己写的代码,可能还需要引用别人的生成代码(标准库或是第三方库,比如例子里的printf.o就是标准库所提供的),而把这些.o文件组织成最终的单一可执行文件,就是链接器的工作。
【进阶】实际上在C语言里,上图的printf函数默认情况下并不是直接通过链接printf.o来使用,C标准库默认以动态链接库的形式存在,在程序被加载器吊起到内存时会挂载所需的动态链接库。当然,这是后话,新人不必急于理解。至于加载器,唔,可执行文件在磁盘里躺着的时候和被加载到内存去执行的时候,结构上还是有些差异的,需要个引导者来做初始化操作。
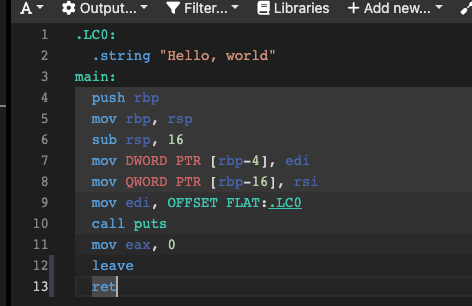
我们来看看,经过编译器编译之后,生成的汇编源代码长什么样,这里我们选取最新的gcc 12.2,先看看在Intel x86-64架构下的生成物:
当他链接成.o的时候,我们看到的则一般被称为反汇编码:
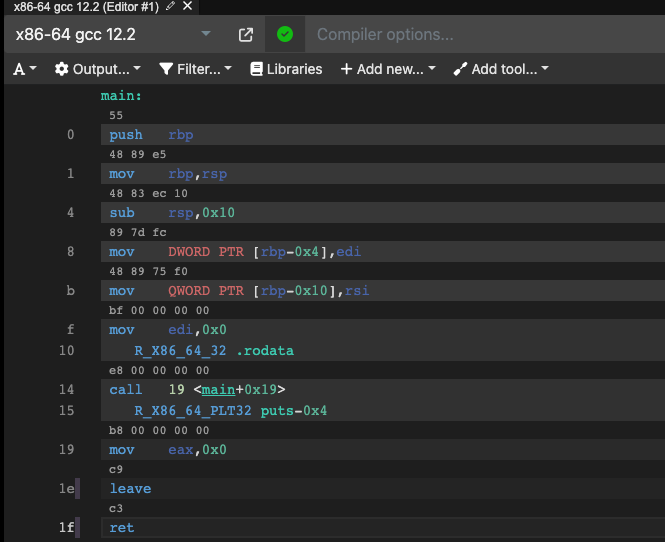
相比后者,提供给汇编器的前者一般会有一些脚手架,用来辅助编写汇编程序,比如.LC0部分的数据段,而后者则是CPU在真实执行时的汇编指令,或者这里叫机器指令更合适。每行汇编指令的上面还显示了对应的机器码,这里使用的是十六进制(只是二进制的一种简化写法,相对来说更加友好)显式。这些机器码就是CPU执行时真正的指令,不同的数字就是0和1的排列组合,表示了不同的功能。
好,让我们换个架构,比如从Intel x86-64换到ARM64,再编译链接一下:
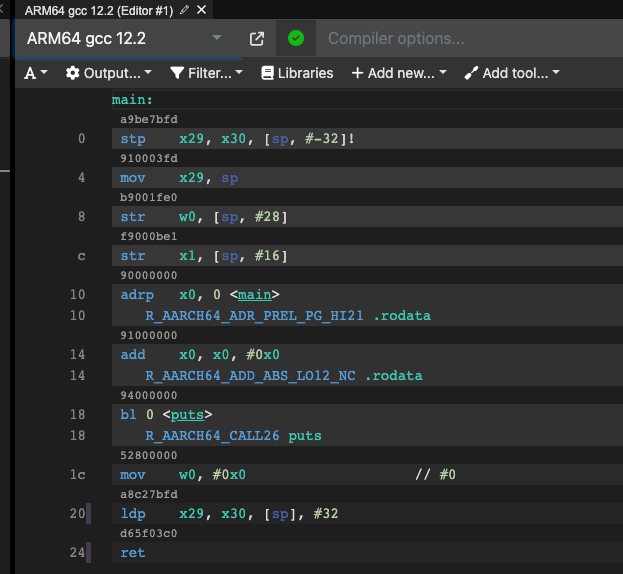
不同的处理器架构指令集的设计千奇百怪,但是对于编写hello.c的开发者来说,我们完全可以不必理解它们,因为这些工作已经由翻译们(编译器)完成了。
Python
Python是一门解释型语言,前面也提到过,解释型语言是聘请了个同声传译,在代码运行时实时翻译成所在架构的机器码,而这个同声传译在这类语言里一般被称为虚拟机(VM,
Virtual
Machine)或是执行引擎(比如Javascript的V8引擎)。当我们在终端执行python
hello.py时,会直接在终端打印出"Hello,
world",他不需要像C语言那样要先编译再执行本体:"gcc hello.c -o hello
&&
./hello",而是直接把.py文件作为参数传给python解释器,python解释器会先把print('Hello, world')翻译成字节码(Opcode,也叫操作码,在Python的世界里指PyCodeObject),再由VM解析字节码实时变成机器码。
字节码不是机器码,它是一些解释型语言在更上层制定的语法规则,它们一般类似机器码也有着像汇编那样的助记符,但所有平台通用(相当于也是个中间层,字节码到机器码的翻译交给了平台上具体的虚拟机)。
【进阶】Python代码执行一般来说经过以下四步:1.将源代码解析为解析树(Parser Tree);2.将解析树转换为抽象语法树(Abstract Syntax Tree);3.将抽象语法树转换到控制流图(Control Flow Graph);4.根据流图将字节码(bytecode) 发送给虚拟机(VM)。
我们看下hello.py在执行时首先被翻译成的字节码:
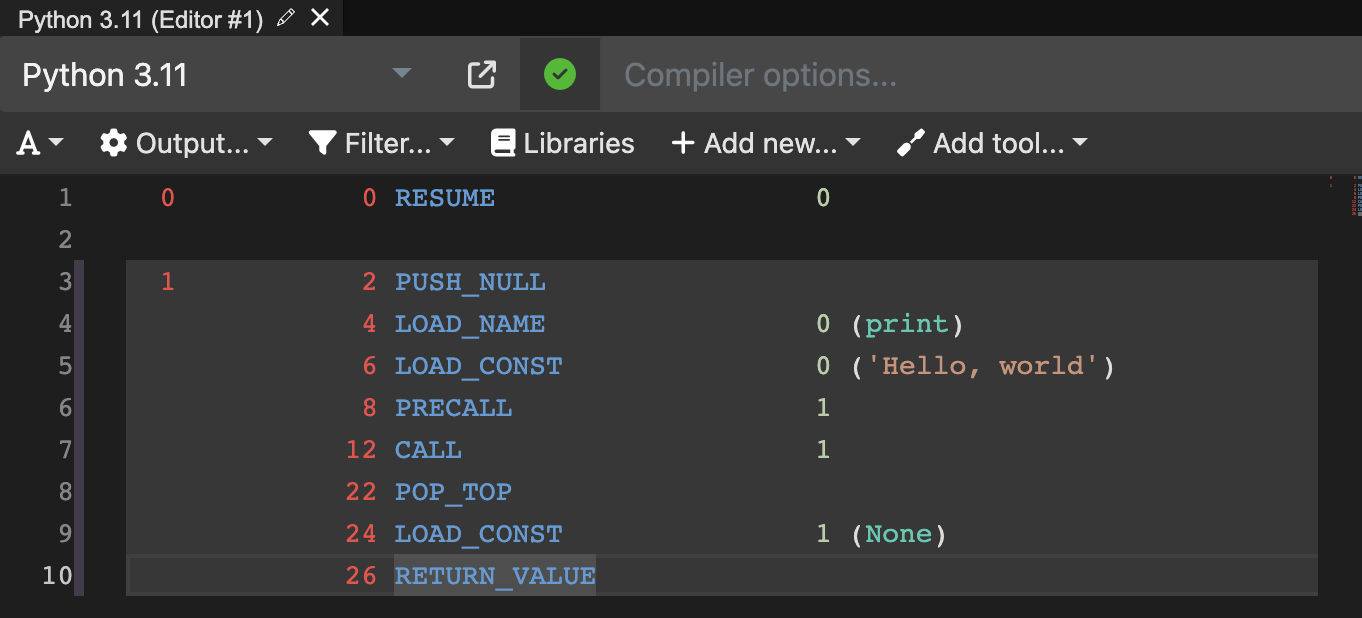
是不是和汇编助记符很像?其实本质上都是一个思想,只是所处的层级不同罢了。
还记得解释型语言相比编译型语言的劣势吗?没错,运行时速度慢!毕竟你同声传译再强,也打不过提前抄标准答案的作弊狗(2023的今天,这话其实也不绝对了,解释型甚至也可以进行实时优化,根据运行时更丰富的信息生成更高效的代码,性能甚至超越编译型)。
Python其实一开始被作者设计出来的时候,仅仅只是当做一个玩具,万万没想到的是,其简约极致的风格收获了大批粉丝,无数大佬先辈把python社区经营的如日中天,随着历史发展,python的语言生态逐渐丰富起来,就像是滚雪球一样,python最终承受了他原本不该承受的国之重任。
就像C可以引用公共库一样,python也有公共库,只不过在python的世界里这叫做“包(package)”,当你需要使用其他人的函数方法时,只需要在文件头去import xxxx即可,这就和C的#include <xxx.h>有异曲同工之妙。为了能够提速,python把可以复用的包在首次执行时翻译生成的字节码转储(dump)到同名的.pyc后缀文件里,嗯,这里面涉及了工程的另一个思想本质:缓存、空间换时间。
所以你看,解释型和编译型的界限在2023的今天已经不是那么泾渭分明,虽然python是一门解释型语言,但到处都有编译型的影子。
Java
Java相比Python,从一开始的设计上就显得更理直气壮了:老子就是半编译、半解释型,你能咋地?Java也使用虚拟机(大名鼎鼎的JVM,
Java Virtual
Machine)和字节码的概念,我们编写的hello.java源文件首先会经过编译(javac hello.java),生成完整的字节码,它被转储到文件.class后缀同名文件,Java编译过程并不会直接生成可执行文件,而是在运行时通过java hello来去自动加载所需的.class并通过JVM去解释opcode,最终转换成特定平台的机器码。
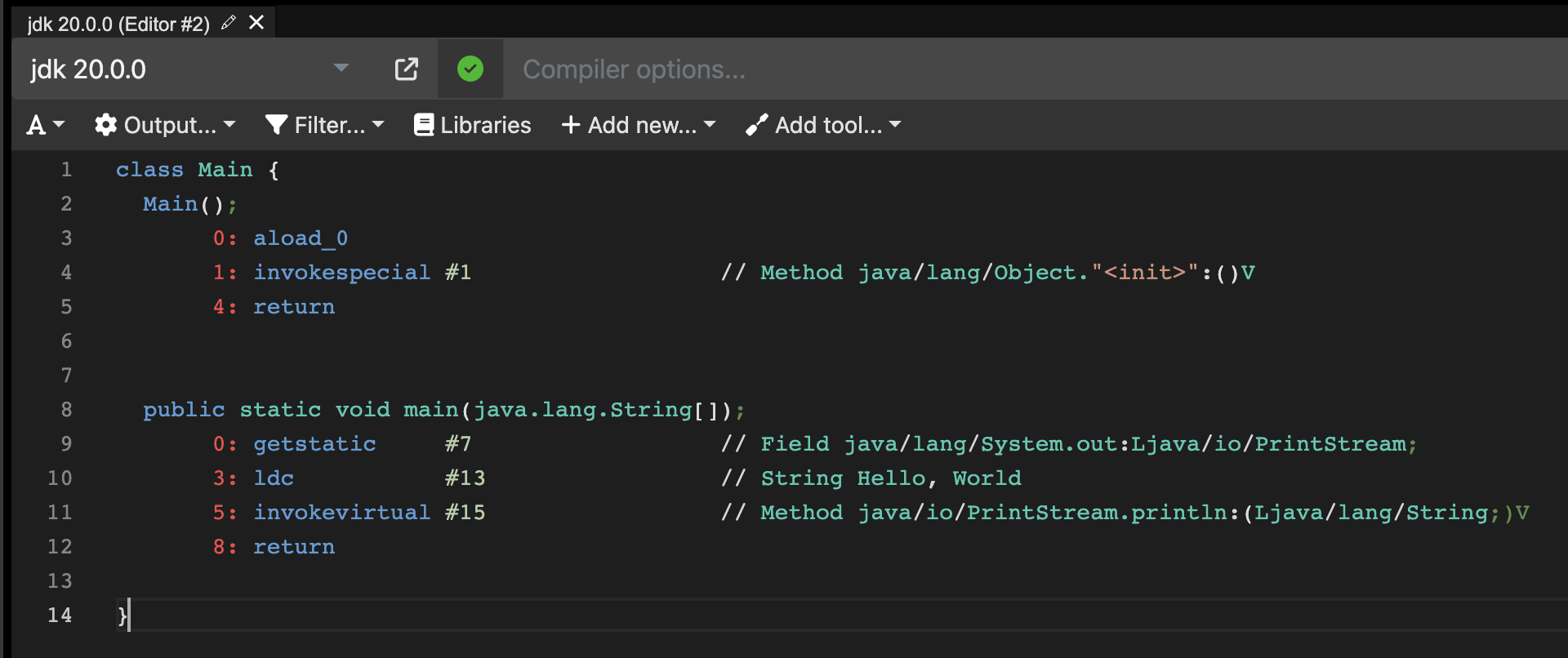
比如上图是一个可视化的Java字节码,它以二进制的形式存储到.class中。
所以Java在江湖上有一句经典口号:一次编译,到处运行!实际上,这就得益于其半编译、半解释的设计,我们在任何平台上都可以先运行编译器把它转成字节码,然后你可以随便拷贝到任何架构上,让特定的架构的JVM充当同声传译,把字节码转成相应的机器码(话虽如此,但也有水土不服的情况,毕竟理想很丰满,厂商很骨感)。
小结
实际上所有的高级语言设计上都可以抽象成这样一个模型:
Source code ---> |Compiler| ---Mid code---> |Runtime| <--- Lib
只不过不同语言各有取舍,每一环节的任务或轻或重罢了。
文本文件?二进制文件?
上面我们曾频频提起文本文件和二进制文件,比如我们说源代码都是文本文件、生成的可执行文件、转储的字节码文件则都是二进制文件。那么二者到底是什么,又有何区别呢?不急,我们先思考这样一个问题:你编写的这些源代码,它们是怎么存放在存储媒介(比如硬盘)的呢?计算机的世界都是0和1,那么每一个字符、每一个汉字都是怎么对应到具体的0和1呢?
如果你理解了前文,那么相信聪明的你已经想到了答案:如法炮制,无非也是制定一个规则,给每个字符都映射一个0和1的排列组合嘛!没错,实际上,这一思想应用在这里,就叫做:“编码”。
编码:从ASCII到UTF8
计算机是美国人发明的,美国人说英语,他们在设计之初为了满足自身使用需求,搞了一套如今广为流传的ASCII(American Standard Code for Information Interchange, 美国信息交换标准代码)码。
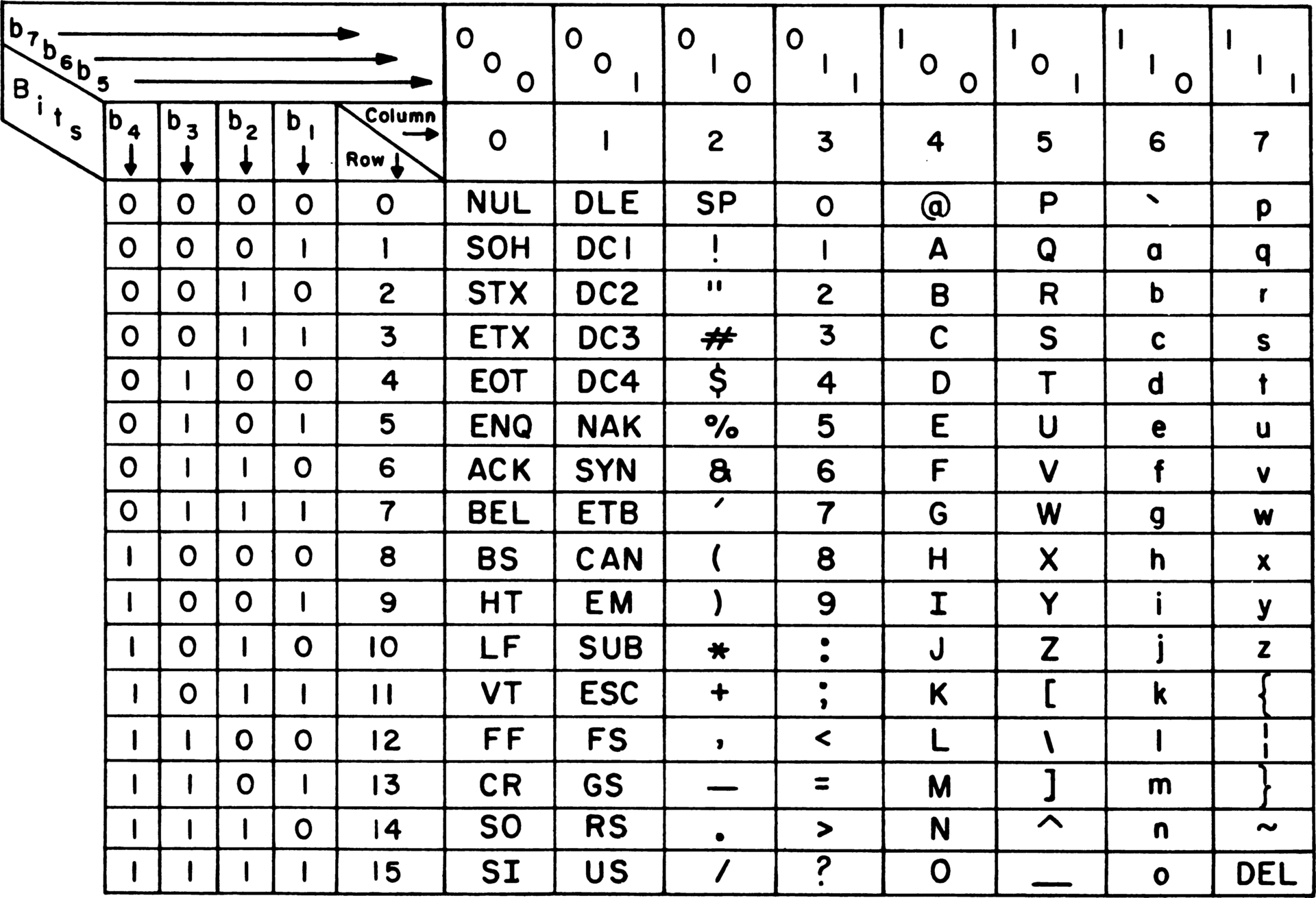
整张映射表对128个字符进行了编码,这其中包括了阿拉伯数字、26个英语字母的大小写、各种普通符号以及一些不可见的控制字符。比如大写字母A对应的ASCII码是65(二进制表示为B0100001),阿拉伯数字0的ASCII码是48(二进制表示为0110000),其他像是空格(SP)、换行(LF)等普通符号与不可见字符也有对应的映射码,它们在表中以大写名称标注。
【维基百科】: ASCII由电报码发展而来。第一版标准发布于1963年,1967年经历了一次主要修订,最后一次更新则是在1986年,至今为止共定义了128个字符;其中33个字符无法显示(一些终端提供了扩展,使得这些字符可显示为诸如笑脸、扑克牌花式等8-bit符号),且这33个字符多数都已是陈废的控制字符。控制字符的用途主要是用来操控已经处理过的文字。在33个字符之外的是95个可显示的字符。用键盘敲下空白键所产生的空白字符也算1个可显示字符(显示为空白)。
由于一共是128个字符,这个量级刚好是2的7次方,换算成2进制的话也就是说至多需要7个二进制位(也叫bit),从B0000000一直到B1111111(这个B前缀是用于表示二进制binary)。为了方便说明,人们一般从低位到高位把每一位进行标号,对应到上图就是b7~b0。
随着计算机在世界范围的普及,ASCII的128个字符就显得捉襟见肘,在流传到一些西欧国家后,大家开始了整活儿,既然128个不够用,那我就扩展一下,加个倍,变成256个总够了吧。嗯,人性都是狭隘且自私的,愚蠢的西方人于是搞了一套EASCII(Extended ASCII)出来,在ASCII的基础上又新增了128个字符(从B10000000到B11111111)用于表示西欧语言的特有字符,包括表格符号、计算符号、希腊字母和特殊的拉丁符号。虽然EASCII解决了部分西欧语言的显示问题,但世界可不止你西欧和北美。一旦把视角切到古老的东方,这些狭隘的编码手法在浩如烟海的象形文字面前显得是那么脆弱,那么的不堪一用。于是乎,在这段历史长河的至暗时刻,大大小小的国际组织、国家都在ASCII的基础上衍化出自己的编码标准,因编码不同而导致的水土不服问题频出。
比如在中国,先后曾衍生出GB2312、GBK、GB18030的编码,这类编码的设计思想就在于:基于128个ASCII,向上扩展到2个字节来表示中文、数学符号、罗马希腊字母、日文假名等等,而128个ASCII则原封不动还是用1个字节来表示,而这就是输入法常提示的全角与半角的由来。
终于,美国人意识到了ASCII设计之初的狭隘,几经辗转,有一个在加州的组织制定了全球统一的编码规则——Unicode(中文名称为统一码,又译作万国码、统一字元码、统一字符编码)。现在的软件系统大多采用Unicode,如XML(Extensible Markup Language,可扩展置标语言)、Java都默认采用Unicode,Unicode不是一种特定的编码,而是更上一层的编码规则,向下有多种具体的编码格式,如今最常用的就是向下兼容ASCII的UTF-8以及和UCS-2兼容的UTF-16。
Unicode一经问世,备受认可,为ISO纳入国际标准,成为通用字符集,即 ISO/IEC 10646(ISO老白嫖怪了,经典操作:方案是你的,但标准我来制定,谁叫你Unicode组织只是个商业机构呢)。
纵观历史长河,我们发现ASCII编码的核心问题在于表示每个字符的bit位太少,所以各种扩展编码都进行了加倍甚至超级加倍的动作,只不过大家的映射表都是自制,因此可能同一个字符在不同编码映射表里的值并不相同,所以当鸡同鸭讲时、鸭听到的全是乱码,这是任由扩展而带来的衍生问题。Unicode大一统后,一概使用一致的字集编码。Unicode默认采用的编码是UCS-2,它采用16位的编码空间(也就是每个字符占用2Bytes,最多可表示2^16=65536个字符),事实上6w+的字符量已经足以cover全球主要语言的大多数字符,但unicode还是提供了一个扩展机制,允许表示一百多万个字符(还能怎样,2个字节不够,那就3个,3个不够就4个)。
为了能够兼容ASCII,像是英文字母“A”,它的ASCII值是65(十六进制表示是0x41, 0x是十六进制hex的前缀),用unicode编码时我们保证其值不发生改变,由于UCS-2是16位,那么高位就用0填充,写成:U+0041。值是相同的,唯一的区别在于,从1个字节变成了2个字节,体积膨胀了一倍。至于各种其他乌七八糟的字符,我们预先按区间划分做dispatch即可,比如中文“一”对应的值是U+4e00(十进制就是19968),舒服了。
UCS-2在设计上和ASCII一样,都是定长编码,其带来的问题就在于对于那些一个Byte(8bit)就足以表达的字符,我们不得不用两个Bytes来存储,这会导致存储上的冗余(存了太多不必要的0x00)。而另一方面,由于像是ASCII囊括的那些字符,往往在日常工作中都是高频出现,这就会进一步加剧存储上的冗余。
现代存储单元的最小单位一般是Byte(字节)。
那么怎么办呢?我们发现罪魁祸首在于UCS-2是定长的,如果我们能设计一种变长的编码,也就是可长可短的编码方式,这个空间浪费问题不就迎刃而解了吗?
但是使用变长又会引入新的问题:我怎么知道这一次解码时,是该取长度1还是长度2呢?所以我们需要制定一种规则,让解码的时候有迹可循。比如,我们设计这样一系列规则:
- 对于单Byte字符,8 bit位中最高位必须等于0(ASCII只有128个嘛,这点可以办到)
- 对于需要N Bytes的字符:
- 首个Byte:
- 高位前N位为
1 - 第N位为
0
- 高位前N位为
- 其余Byte:
- 高位以
10开头
- 高位以
- 未提及的位使用对应的unicode补充,不足的在高位用0补充
- 首个Byte:
实际上这就是UTF-8编码,文字说起来很抽象,用图表展示会更直观:
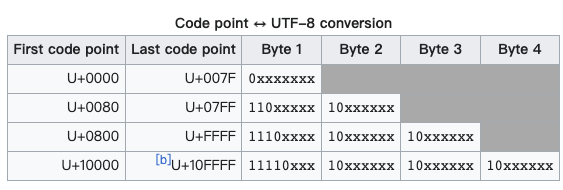
经过这种方式,我们在解码时就可以根据第一个Byte的控制头来识别到底是要连续读入几个Byte,又要怎么把他们还原成原始code。那么现在我有个问题留给你思考:为啥其余Byte也要安排个10控制头呢?
经过UTF-8编码,我们的字符就变成了这样:
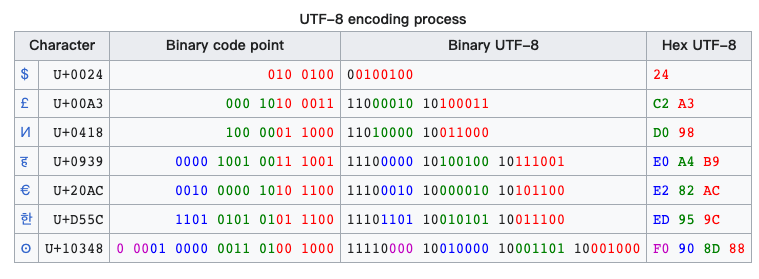
除了UTF-8以外,还有其他的编码方式,比如UTF-16(2或4字节变长)、UTF-32(4字节定长)。
细心的读者可能会发现这样一个问题:变长编码虽然解决了单字节变双字节存储冗余的问题,但由于控制字符的存在也引入了额外成本,一些字符可不仅仅是2个字节,而是3个甚至是4个(比如汉字通通都是3个),而这对比UCS-2或者是像中文的GB2312,GBK,GB18030来说,对于存储汉字实际上也是会造成冗余的。
UTF-8确实有着这一问题,但其设计实际上是早期互联网传输的带宽限制与国际字符互通的双向妥协(彼时本地存储的价格已经被降得很低,不再成为瓶颈)。因此,在2023的今天,你可能还能找到一些使用GBK等中文字符集的场景(比如MySQL),甚至可能还会有C语言遗老跟你讲strlen和中文字符长短的故事。毕竟对于包含大量中文的文本文件,使用GBK编码相比UTF-8确实能省近乎1/3的存储空间。
文本文件
使用各种编码编写的文本,存储到文件里,这个文件就被称作“文本文件”。我们平时使用编辑器去展示和修改文本内容,实际上这一过程都是经过编解码处理的(你书写的字符经过编码存储到底层文件,编辑器把文件里的数据解码成字符显示出来)。一些常用编辑器乃至IDE(Integrated Development Environment, 集成开发环境)都有选择使用何种编码的功能,即使是Windows的记事本也有着多种编码供你选择(其中就包括UTF-8)。
如果我们使用二进制编辑器打开编写的hello.c,就会看到磁盘里存储的实际上正是编码后的01序列。

二进制文件
除了文本文件以外,其他文件都是二进制文件。实际上二者本质并没有什么不同,你完全可以把文本文件当成一种特殊的二进制文件,业界之所以有这样的流行概念来加以区分,无非是因为很多标准、API的设计木已成舟,比如C标准库和POSIX的文件接口设计,就有着针对二者的区分。
每种不同的二进制文件都有着自己的格式,比如前文所讲的:hello.c编译链接生成的二进制可执行文件就有着自己的格式。

二进制编辑器毕竟不是可视化的,对于不同种类的二进制文件一般需要特定的编辑器才能可视化,比如图片也是二进制文件,但像是PhotoShop、美图秀秀这类可视化编辑软件却可以呈现图片的内容,这一过程本质上和文本编辑器打开文本文件没有什么区别。我们用二进制编辑器打开上面的图片,看看它里面的数据:
肉眼根本无法理解,我们没办法直接从这些二进制数据在脑海中还原出它是怎样的一张图,只能隐约看到一些“性状特征”:比如有个png字符躺在最前面,它其实是png类型文件的标志头。
电影《黑客帝国》的大佬可是手改二进制,大脑里自动还原成小电影的哦,恐怖如斯!
机器码执行简述
一个经典的硬件系统组成结构如图:
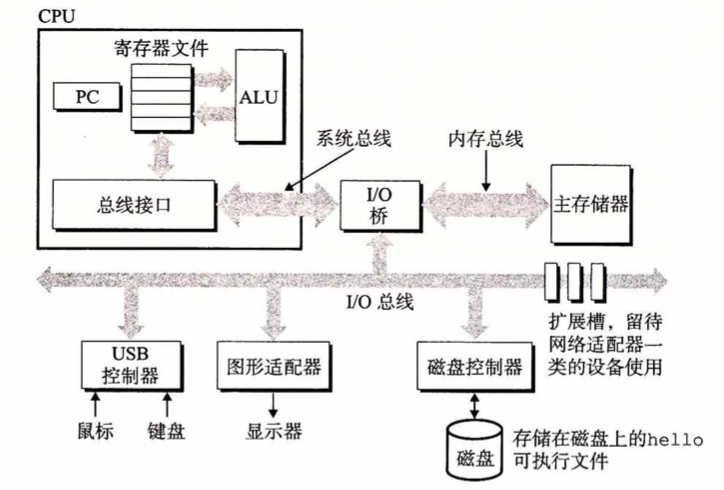
我们的程序被操作系统加载到内存之后,最终的机器码是交由CPU来一条条执行的。这些机器码在可执行文件中也以数据的形式存在(遵循冯诺依曼架构)。CPU内部被拆分成控制单元、运算/逻辑单元(ALU)和寄存器(Register),ALU负责计算、寄存器负责暂存数据、控制器负责在内存、总线和寄存器之间传递数据。内存是一种临时的存储设备,关机之后它的数据会全部丢失,而我们的程序字节码平时是躺在可执行文件中寄放在硬盘上的,硬盘是一种持久化的数据存储,关机并不会擦除已经写入的数据。因此,在计算机运行期间,加载器把可执行文件加载到内存(当你双击打开exe的时候),里面的机器码通过总线送到CPU的ALU,然后一条条指令执行下去。
【维基百科】冯·诺伊曼结构(英语:Von Neumann architecture),也称冯·诺伊曼模型(Von Neumann model)或普林斯顿结构(Princeton architecture),是一种将程序指令存储器和数据存储器合并在一起的电脑设计概念结构。存储程序计算机在体系结构上主要特点有:1.以运算单元为中心 2.采用存储程序原理 3.存储器是按地址访问、线性编址的空间 4.控制流由指令流产生 5.指令由操作码和地址码组成 6.数据以二进制编码
为什么内存不做成持久化的呢?一方面是成本问题,另一方面则是没有必要。内存相比机械硬盘哪怕是固态它的速度完全不在一个量级上,像我们的PC,硬盘动不动就1TB、2TB,但内存可能只有16GB、32GB。DRAM的随机读取要比你SATA的随机读取快上1000倍。
那么为什么需要寄存器呢?答案很简单:要提速。尽管内存相比硬盘,它的速度快上了好几个量级,但是对于以纳秒为量纲的现代处理器来说,完全不在一个次元。因此CPU会设计出或多或少的寄存器在内存和ALU之间传话(如果说ALU是皇帝,内存是大臣,那么寄存器就是太监),不同的CPU架构有着不同数量的寄存器,每个寄存器都有它自己的用途,而寄存器的大小则取决于总线的宽度(也就是你一次性最多能传输多少bit数据),比如对于64位系统来说,寄存器的存储空间就是64bit=8Bytes大小。寄存器相比从内存读取数据还要再快上100倍(在2023年的今天,可能远远不止100倍了),但寄存器毕竟存储量级受限于总线宽度与个数,从制作成本和设计上来讲,想要完全通过寄存器来满足针对内存使用上的提速是远远不够的。那怎么办呢?既然寄存器造价太高,我们何不找个折中的法子:做一个中间缓存层,挑一种比DRAM更快且比寄存器更能吃的硬件如何?而这就是现代处理中颇为重要的一个概念:高速缓存。
高速缓存采用的是一种叫SRAM的存储媒介,相比DRAM它的速度更快但相应的造价也更高。而这一中间层能够起到高额的缓存命中率,本质上的原因在于:我们CPU去执行的指令或者取的数据往往都具有局部连续性,比如一大段机器指令是加载到连续的一段内存,所以在CPU通过总线去取某一条指令的时候,实际上会一次性批量把连续的内存数据(此时就是连续的机器指令)全部拿到并置入高速缓存,等到我们需要继续执行下一条机器码指令时,缓存直接命中进而达成提速的效果。
实际上现代处理器不仅有缓存,甚至是多级缓存,比如经典的三级缓存模型:
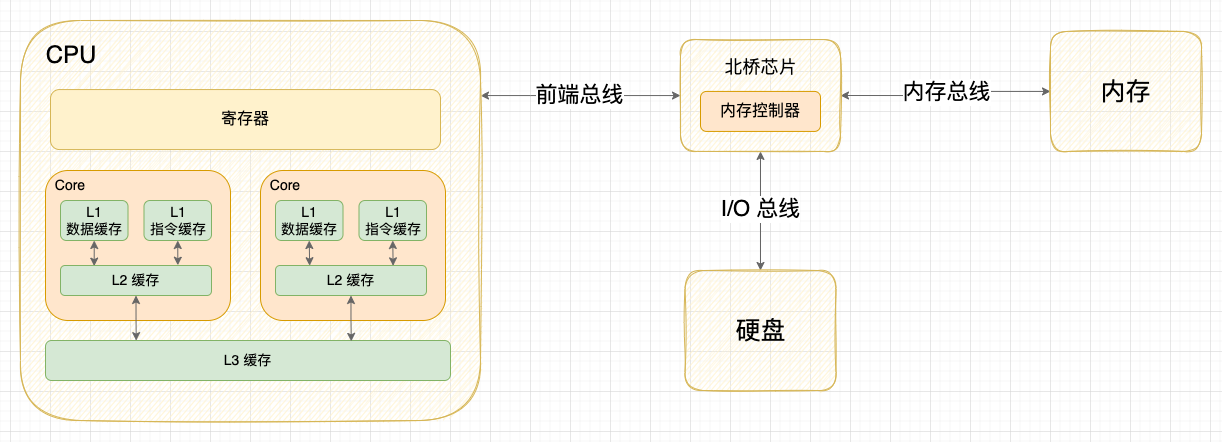
自顶向下容量逐渐增大,访问速度也逐渐降低。当缓存未命中时,缓存系统会向更底层的层次搜索。
- L1 Cache: 在CPU核心内部,分为指令缓存和数据缓存,分开存放CPU使用的指令和数据;
- L2 Cache: 在CPU核心内部,尺寸比L1更大;
- L3 Cache: 在CPU核心外部,所有CPU核心共享同一个L3缓存。
越顶层的缓存为了提升命中率,功能分类会越细致,层层漏斗下去,最终走到内存。整个计算机系统的存储设备可以组织成一个金字塔型:
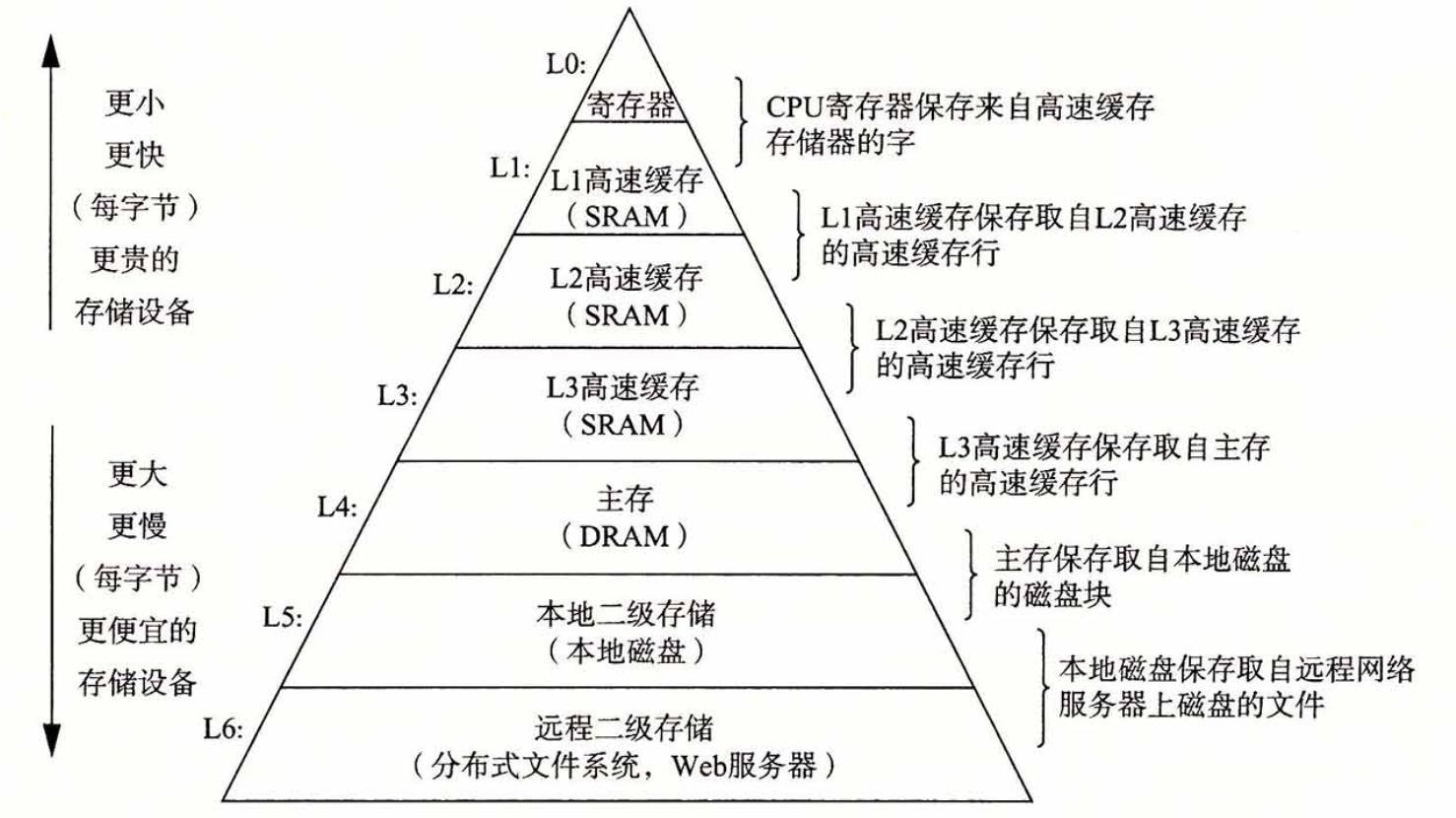
这一张图可谓是把工程实践中“分层”与“缓存”的概念发挥得淋漓尽致。
操作系统眼里的程序
一个程序从编写到执行的整个过程,目前就仅剩一个环节就可以完整的自顶向下串起来了,那就是:程序从磁盘上加载到内存的过程。这一步骤由操作系统的加载器完成,它会把躺在硬盘上的可执行文件加载映射到内存中,作为一个独立的进程存在,拥有着自己独立的虚拟内存地址空间。
进程(Process)
这里就提到了一个在操作系统中非常重要的概念:进程。我们在学操作系统这门课时,老师往往要求熟读并背诵这样两个概念:进程是资源分配的基本单位;线程是任务调度和执行的基本单位。这两句真言本身并没有错,但对于初学者来说确是难以理解的学术派黑话。什么他么资源分配、任务调度,究竟到底什么是进程?
我们来打个比方:可执行文件躺在硬盘里的时候,你可以把它看成是一种被冻结的生命模板,而在加载到内存后,模板被唤醒克隆出一个新的生命。每个生命体都是一个进程,进程在操作系统里有着唯一的ID标识,同一个生命模板也可以被加载多次,但是它们每次克隆出的都是新生命,彼此隔离。进程实际上是操作系统对一个正在运行的有生命的程序的一种抽象,为什么说它是资源分配的基本单位呢?因为在现代操作系统中,每个进程都有独立的虚拟内存地址空间(当然,不止这一种资源),站在每个进程的第一人称视角来看,它都在独占硬件(处理器、内存和I/O设备),进程之间彼此隔离,谁也看不到谁,只有操作系统才知晓所有进程的存在。
但是我们知道,硬件设备是唯一的,内存需要大家共享,CPU即使有多核,它的核数也是先天锁定的(你总不能说我CPU就8核,那进程只能有8个吧)。当我们把视角从进程第一人称切到上帝(操作系统)视角来看,就会发现其实每个进程都在交错、并发执行(也就是说轮换着共用多个CPU核)。为什么说是既交错又并发呢?因为进程数往往是远超CPU核数的,所以当多个进程同时在运行的时候,操作系统就得通过某种策略去调度分配,比如我一共有8核,那么在t0时刻,就会有8个进程在同时运行,而等到t1时刻,可能相比t0发生了轮换,此时是另外8个进程同时运行(可能和t0的8个有重叠:可能是连续执行了完整的duration,也可能是被换出之后又换入)。
简单来说,CPU有多少核,就支持同时执行多少条指令。虽然这样说并不严谨,毕竟现代CPU往往有线程超卖的设计,但不妨碍理解。
不同类型的操作系统有着迥然不同的调度策略,类型上一般是分为实时操作系统和分时操作系统。我们平时使用的大部分OS像是Windows,Linux都是分时操作系统,它们有时间片的概念,时间片到期或进程(线程)主动让出的时候会让给其他进程(线程)。
而内存则一般是做了一层从物理内存到虚拟内存的映射,操作系统会欺骗每个进程:你们都在独立使用整块DRAM(甚至超卖,比如对32位系统来说有4GB大小的虚拟内存空间,但物理内存DRAM可能只有2G),而只有在进程真正去读写某一小块特定的地址时,操作系统才会真正把物理内存交给你使用。
虚拟内存:线性地址空间
虚拟内存空间按地址进行索引,整片空间是连续线性的,而地址空间的大小取决于系统位数,对于32位机器来说,这个大小就是4GB,对于现如今最常见的64位机器来说,大小甚至达到了256TB。
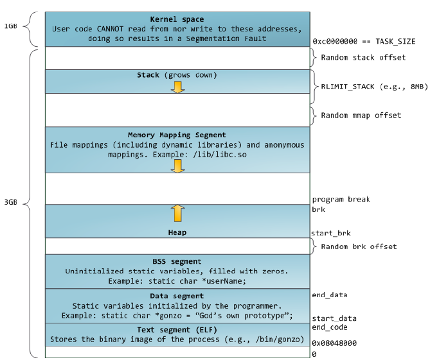
比如上图是一个进程在32位 Linux系统上的线性地址空间图,它被分割成了多段,每一段存放特定的资源,比如:代码段(也就是你程序编译链接后的机器码)、数据段、堆(Heap)、栈(Stack)等等。整个寻址空间有4GB的大小,地址范围从0x00000000到0xffffffff。
【进阶】在32位 Linux上默认情况下高1GB是内核空间,所有进程共享。低3GB才是进程在用户态可用的线性地址空间。Windows上则默认是高2GB为内核空间,嗯,Windows内核真大。
线程(Thread)
实际上并发执行并不仅限于多个进程,在现代操作系统中,每个进程内部其实也可以并行执行多个任务,而这,就引出了线程。进程可以管理多个线程,每个线程负责一条控制流,它们共享所属进程的同一片线性地址空间(也就是说彼此天然就看得见),但各自有着私有的资源(比如每个线程都有自己的Stack)。对于那些只有一条控制流的进程,进程或是线程的概念可能显得没那么重要,事实上进程和线程只是现代操作系统抽象出的概念,它们在不同的操作系统里的设计各有差异,在Windows中,进程和线程可以说是一板一眼,进程就是个空壳子,对于那些只有一个控制流的进程它们默认会有一个主线程。而在Linux中情况就比较复杂,进程和线程的概念受历史原因有过多次改版升级,所以并不像Windows那样纯粹。
【进阶】Linux内核弱化了进程、线程的概念(不像Windows进程严格管理线程,调度单位只能是线程,弱化了进程父子关系,使得进程看起来可以通过CreateProcess凭空捏一个出来),内核都是task_struct统一管理,比如
vfork()出来的轻量级进程甚至可以与其他进程共享线性地址空间(只不过有个额外标志)。由于历史原因,Linux也遵守了真香定律。以pthread的两种实现LinuxThread(Linux2.4以前)和NPTL(2.5以后)为例,早期内核是没有TGID的,只有PID,所以内核根本就没有线程的概念,在内核眼里都是进程,都是调度器调度的单元,而这就给LinuxThread的实现带来了难题——LinuxThread采用1:1模型,即每个线程都是LWP对应一个内核线程(这个线程的概念是从我们的视角出发的)。而NPTL时代,内核引入TGID,此时依然是1:1模型,但不是简单的LWP了,TGID把这些线程联系了起来,NPTL创建线程时传递一个特有的CLONE_THREAD标志,内核把TGID填写为调用者的PID,PID填写新线程号(原本的进程号)。
为了便于理解,我们采用Windows的视角,统一把线程视为执行流,进程视为管理员。因此CPU核的切换实际上是发生在线程上的,那么线程1是怎么切换到线程2上的呢?我们之前说切换的动作需要内核代码来做,内核代码是运行在内核态的,而我们的代码运行在用户态,怎么就跑着跑着就丢了,就执行到内核的切换代码去了呢?
事实上,每一个用户态的进程在运行时都会经常进入到内核态,当我们调用了一些系统调用(system call)的时候,就会从用户态切换到内核态,比如我们的程序进行了文件I/O、网络I/O、各种资源申请等等操作(一般会引起阻塞)时都会发生这一切换,在内核态想要切换回用户态的前夕,根据操作系统的类型以及调度策略,会去判断是否要将当前所用的CPU核轮换给另一个嗷嗷待哺的线程(比如时间片过没过期啊,优先级啊等等)。
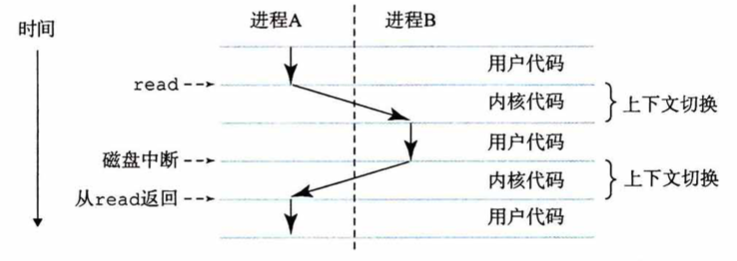
你可能会问,假如我写个死循环在那里空转,我绝对不自己触发系统调用,那我的CPU核不就没机会让出去了吗?虽然你的想法很危险,但这确实是一个好问题。实际上,现代操作系统内核里还有个特等公民:中断。中断优先级高于内核线程,一旦发生了中断那么一定得让出一个CPU核来立即响应(中断在内核态的地位就好比Linux系统里信号在用户态的地位)。中断处理告一段落后,才会返还给内核线程,此时就产生了线程切换的时点。中断有很多种,这其中用于保证现代操作系统能够进行线性调度的那位爷叫”时钟中断“,时钟中断会通过硬件定时产生,所以年轻人,躲得了初一、躲不了十五。
还有个缺页异常(Page Fault)中断也很重要,它是实现每个进程的虚拟内存地址空间的基石,日后我们讲具体的操作系统时再做展开。
通信与竞态
同一个进程下的多个线程彼此是看得见的,因此它们完全可以在用户态互通往来,A1看得见A2,A2也看得见A1,但是A1和A2都无法看见另一个进程B下的B1, B2...另一方面,并发相比单一执行流虽然效率上成倍增长,但也带来了一个新问题:竞态(Race Condition,也程竞争条件、竞争冒险),它旨在描述一个系统或者进程的输出依赖于不受控制的事件出现顺序或者出现时机。此词源自于两个信号试着彼此竞争,来影响谁先输出。当线程A1和线程A2同时试图修改一块内存,在没有并发控制的情况下,最后的结果依赖于两个进程的执行顺序与时机,并发访问冲突可能会导致最后的结果不符合预期。
那么怎么解决竞态问题呢?这就需要我们对共同访问的资源(一般被称为临界区)进行互斥保护,操作系统API乃至一些现代高级语言本身都提供了各种保护的手段,归纳来讲其实就两种思路:”上锁“和”执行不可打断“。锁的设计多种多样,它的思想就是:卫生间就一个,你先进去了就要锁门,防止别人在你答辩的时候误入。等你舒服了之后,锁才会被释放,其他人才有机会使用。而所谓的执行不可打断,就是指我整个过程一气呵成,从所有人的视角看整个动作都是一瞬间完成的,不会被中途打断,也就从根源上避免了竞态,我们一般称其为”原子操作“(这一命名较为古老,是取原子为最小单元不可再拆分之意)。
当然竞态不一定非要是多核环境下才能触发,即使你只有单核,但是由于CPU轮换调度机制,你的线程A1完全可能在临界区操作中途被打断,换给了A2,而A2又进入了临界区开始操作,此情此景亦会产生竞态。
实际上我们把镜头拉起,除了同一进程下的多个线程可能会发生竞态以外,即使是多个进程之间也可能会产生竞态。尽管进程之间彼此看不到(主要是看不到彼此的地址空间和独有资源),但它们可能会共同修改同一个磁盘上的文件,我们回过头思考:线程之间的竞态解决本质上是靠线程之间彼此的交互来达成的,这对于进程来说也是一样,但进程天然彼此隔离,所以就需要操作系统去提供一些通信的手段来让进程之间也能互通往来,而这就是大名鼎鼎的IPC(Inter-Process Communication, 进程间通信(Inter-Process Communication))。进程通信手法多种多样,具体则视操作系统的实现,日后我们有机会讲某一个操作系统时再做展开。
当然,进程通信并不只是为了解决竞态,它原本的目的就是通信本身。不同进程、或是相同程序的不同进程实例之间需要交流的场景非常繁杂,甚至并不局限于同一台机器,即使是两台机器之间,也可以通过网络I/O来达成RPC(Remote Procedure Call, 远端过程调用)。RPC这一概念在2023的今天相当流行,毕竟微服务盛行,服务与服务之间都是通过RPC请求来做server/client级联交互。
相对于RPC的是LPC(Local Procedure Call,本地过程调用),也就是同一台机器不同进程之间调用(A进程调用B进程的某个接口),只不过LPC的工作都是由IPC完成的(可以这样理解:LPC和RPC在概念上都属于上层,而IPC则是一种实现机制,是底层基础,甚至类Unix系统里都抛弃了LPC的概念,它们认为RPC是LPC能力的超集)。
协程(Coroutine)
协程(Coroutine,也称作微线程(micro-thread)、纤程(fiber))是近些年才兴起的概念,简单来说,它是一种用户态的轻量级线程。线程是操作系统的概念,物理CPU的调度是在线程之间进行轮转切换,前面我们有提到:CPU在线程之间的切换需要有一个从用户态陷入到内核态的过程,而这个过程实际上是有较高的开销的。另一方面,尽管多线程可以成倍提速(比如对于服务器来说,每个请求进来我都开个线程单独处理),但因线程本身占用资源较多,在系统内受物理资源(CPU核数、内存)限制,数量并不是多多益善(像是服务器一般要做池化管理)。而协程相比线程来说,在面向高并发场景的服务器开发来说,其天然的特性得到了发挥,相比线程具有相当的优势。
在2023的今天,许多高级语言都内置了协程的能力,像是C++、Python,甚至像Go语言天然就基于协程来编程。
C++在20标准通过了无栈协程coroutine,但仅仅包含了编译器需要实现的底层功能(语法上形如co_await balabala...),通用API的实现Executors已确认会在23标准纳入,同时还会纳入networking库。
Python从最初的半协程:生成器yield到asyncio、async/await、asynico,协程的体系不断被完善。
协程之间的切换在用户态完成,并不会陷入到内核,且协程本身占用资源较少,这在异步编程的场景中,极大地节省了开销、提高了性能,于此同时,在大部分编程语言中,协程由于其可以采用结构化并发的编程技法,使得相比传统编写异步代码的Callback Hell或是Promise/Future来说,编写得到了简化、代码可读性与维护性也更高。
当然协程本身的实现颇为复杂,想要对协程有深刻的理解需要具备相当的异步编程经验(常见于服务器后台网络编程),作为编程导论,我们浅尝辄止,留待日后专题展开。
总结
系统漫游作为开篇第零章,旨在让每一位开发者对自己在用的计算机有一个宏观的、整体能够衔接上的理解。本文谈及的知识点涉及了计算机的基本组成、操作系统、编程语言等专题,通过抽丝剥茧、层层递进的方式带领读者步入编程世界的大门。我们在学习一门技法的同时,一定要养成思考的习惯,如此方能将杂糅零碎的知识点拼凑成完整的体系结构,知其所以然。一旦知识体系成型,日后对于新知识的吸纳将显得顺理成章、自然而然,疑难杂症的排查亦可心中有数、有迹可循。
by 玉涵,完稿于2023年4月22日深夜,雨