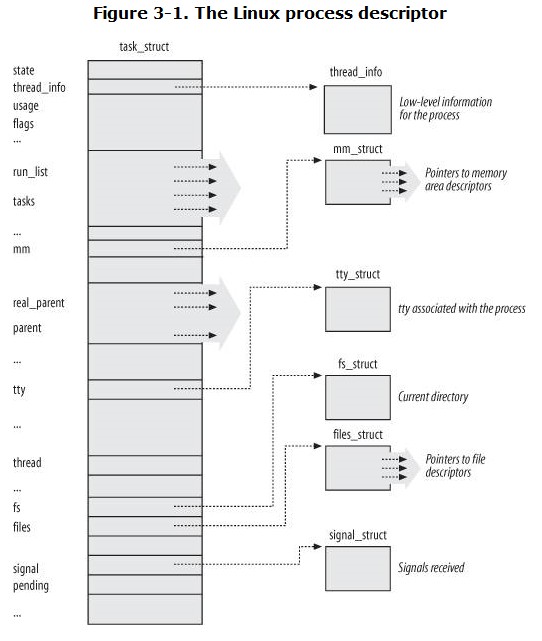
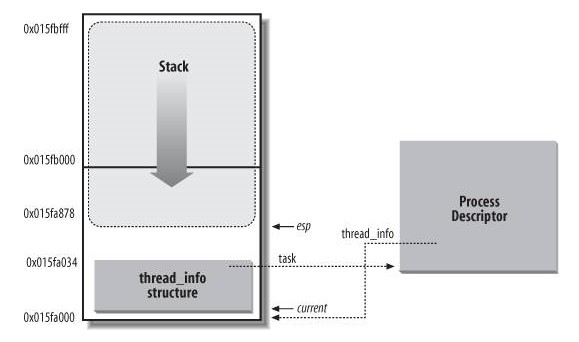
/** * 通过此链表把所有进程链接到一个双向链表中。 */ structlist_head tasks; /* * ptrace_list/ptrace_children forms the list of my children * that were stolen by a ptracer. */ /** * 链表的头。该链表包含所有被debugger程序跟踪的P的子进程。 */ structlist_head ptrace_children; /** * 指向所跟踪进程其实际父进程链表的前一个下一个元素。 */ structlist_head ptrace_list;
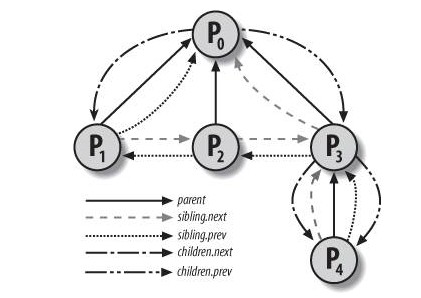
/* task state */ structlinux_binfmt *binfmt; long exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ /* ??? */ unsignedlong personality; /** * 进程发出execve系统调用的次数。 */ unsigned did_exec:1; /** * 进程PID */ pid_t pid; /** * 线程组领头线程的PID。 */ pid_t tgid; /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->parent->pid) */ /** * 指向创建进程的进程的描述符。 * 如果进程的父进程不再存在,就指向进程1的描述符。 * 因此,如果用户运行一个后台进程而且退出了shell,后台进程就会成为init的子进程。 */ structtask_struct *real_parent; /* real parent process (when being debugged) */ /** * 指向进程的当前父进程。这种进程的子进程终止时,必须向父进程发信号。 * 它的值通常与real_parent一致。 * 但偶尔也可以不同。例如:当另一个进程发出监控进程的ptrace系统调用请求时。 */ structtask_struct *parent; /* parent process */ /* * children/sibling forms the list of my children plus the * tasks I'm ptracing. */ /** * 链表头部。链表指向的所有元素都是进程创建的子进程。 */ structlist_head children; /* list of my children */ /** * 指向兄弟进程链表的下一个元素或前一个元素的指针。 */ structlist_head sibling; /* linkage in my parent's children list */ /** * P所在进程组的领头进程的描述符指针。 */ structtask_struct *group_leader; /* threadgroup leader */
unsignedlong ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ /* * current io wait handle: wait queue entry to use for io waits * If this thread is processing aio, this points at the waitqueue * inside the currently handled kiocb. It may be NULL (i.e. default * to a stack based synchronous wait) if its doing sync IO. */ wait_queue_t *io_wait; /* i/o counters(bytes read/written, #syscalls */ u64 rchar, wchar, syscr, syscw; #if defined(CONFIG_BSD_PROCESS_ACCT) u64 acct_rss_mem1; /* accumulated rss usage */ u64 acct_vm_mem1; /* accumulated virtual memory usage */ clock_t acct_stimexpd; /* clock_t-converted stime since last update */ #endif #ifdef CONFIG_NUMA structmempolicy *mempolicy; short il_next; #endif };
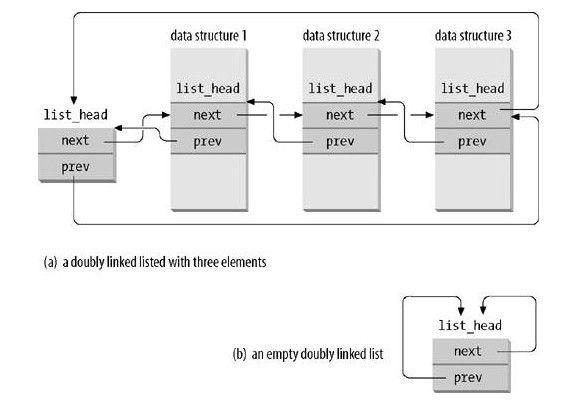
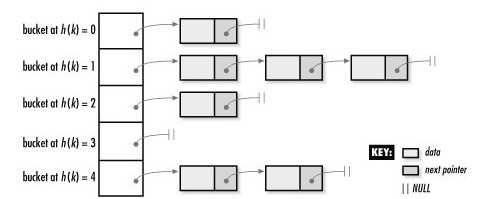
/* * Simple doubly linked list implementation. * * Some of the internal functions ("__xxx") are useful when * manipulating whole lists rather than single entries, as * sometimes we already know the next/prev entries and we can * generate better code by using them directly rather than * using the generic single-entry routines. */
#define INIT_LIST_HEAD(ptr) do { \ (ptr)->next = (ptr); (ptr)->prev = (ptr); \ } while (0)
/* * Insert a new entry between two known consecutive entries. * * This is only for internal list manipulation where we know * the prev/next entries already! */ staticinlinevoid __list_add(struct list_head *new, struct list_head *prev, struct list_head *next) { next->prev = new; new->next = next; new->prev = prev; prev->next = new; }
/** * list_add - add a new entry * @new: new entry to be added * @head: list head to add it after * * Insert a new entry after the specified head. * This is good for implementing stacks. */ /** * 把元素插入特定元素之后 */ staticinlinevoidlist_add(struct list_head *new, struct list_head *head) { __list_add(new, head, head->next); }
/** * list_add_tail - add a new entry * @new: new entry to be added * @head: list head to add it before * * Insert a new entry before the specified head. * This is useful for implementing queues. */ /** * 把元素插到特定元素之前。 */ staticinlinevoidlist_add_tail(struct list_head *new, struct list_head *head) { __list_add(new, head->prev, head); }
/* * Insert a new entry between two known consecutive entries. * * This is only for internal list manipulation where we know * the prev/next entries already! */ staticinlinevoid __list_add_rcu(struct list_head * new, struct list_head * prev, struct list_head * next) { new->next = next; new->prev = prev; smp_wmb(); next->prev = new; prev->next = new; }
...
/* * Delete a list entry by making the prev/next entries * point to each other. * * This is only for internal list manipulation where we know * the prev/next entries already! */ staticinlinevoid __list_del(struct list_head * prev, struct list_head * next) { next->prev = prev; prev->next = next; }
/** * list_del - deletes entry from list. * @entry: the element to delete from the list. * Note: list_empty on entry does not return true after this, the entry is * in an undefined state. */ /** * 删除特定元素 */ staticinlinevoidlist_del(struct list_head *entry) { __list_del(entry->prev, entry->next); entry->next = LIST_POISON1; entry->prev = LIST_POISON2; }
...
/** * list_empty - tests whether a list is empty * @head: the list to test. */ /** * 检查指定的链表是否为空 */ staticinlineintlist_empty(conststruct list_head *head) { return head->next == head; }
...
/** * list_entry - get the struct for this entry * @ptr: the &struct list_head pointer. * @type: the type of the struct this is embedded in. * @member: the name of the list_struct within the struct. */ /** * 返回链表所在结构 */ #define list_entry(ptr, type, member) \ container_of(ptr, type, member)
/** * list_for_each - iterate over a list * @pos: the &struct list_head to use as a loop counter. * @head: the head for your list. */ /** * 扫描指定的链表 */ #define list_for_each(pos, head) \ for (pos = (head)->next; prefetch(pos->next), pos != (head); \ pos = pos->next)
/** * __list_for_each - iterate over a list * @pos: the &struct list_head to use as a loop counter. * @head: the head for your list. * * This variant differs from list_for_each() in that it's the * simplest possible list iteration code, no prefetching is done. * Use this for code that knows the list to be very short (empty * or 1 entry) most of the time. */ #define __list_for_each(pos, head) \ for (pos = (head)->next; pos != (head); pos = pos->next)
/** * list_for_each_prev - iterate over a list backwards * @pos: the &struct list_head to use as a loop counter. * @head: the head for your list. */ #define list_for_each_prev(pos, head) \ for (pos = (head)->prev; prefetch(pos->prev), pos != (head); \ pos = pos->prev)
/** * list_for_each_safe - iterate over a list safe against removal of list entry * @pos: the &struct list_head to use as a loop counter. * @n: another &struct list_head to use as temporary storage * @head: the head for your list. */ #define list_for_each_safe(pos, n, head) \ for (pos = (head)->next, n = pos->next; pos != (head); \ pos = n, n = pos->next)
/** * list_for_each_entry - iterate over list of given type * @pos: the type * to use as a loop counter. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ /** * 与list_for_each相似,但是返回每个链表结点所在结构 */ #define list_for_each_entry(pos, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member); \ prefetch(pos->member.next), &pos->member != (head); \ pos = list_entry(pos->member.next, typeof(*pos), member))
/** * list_for_each_entry_reverse - iterate backwards over list of given type. * @pos: the type * to use as a loop counter. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry_reverse(pos, head, member) \ for (pos = list_entry((head)->prev, typeof(*pos), member); \ prefetch(pos->member.prev), &pos->member != (head); \ pos = list_entry(pos->member.prev, typeof(*pos), member))
/** * list_prepare_entry - prepare a pos entry for use as a start point in * list_for_each_entry_continue * @pos: the type * to use as a start point * @head: the head of the list * @member: the name of the list_struct within the struct. */ #define list_prepare_entry(pos, head, member) \ ((pos) ? : list_entry(head, typeof(*pos), member))
/** * list_for_each_entry_continue - iterate over list of given type * continuing after existing point * @pos: the type * to use as a loop counter. * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry_continue(pos, head, member) \ for (pos = list_entry(pos->member.next, typeof(*pos), member); \ prefetch(pos->member.next), &pos->member != (head); \ pos = list_entry(pos->member.next, typeof(*pos), member))
/** * list_for_each_entry_safe - iterate over list of given type safe against removal of list entry * @pos: the type * to use as a loop counter. * @n: another type * to use as temporary storage * @head: the head for your list. * @member: the name of the list_struct within the struct. */ #define list_for_each_entry_safe(pos, n, head, member) \ for (pos = list_entry((head)->next, typeof(*pos), member), \ n = list_entry(pos->member.next, typeof(*pos), member); \ &pos->member != (head); \ pos = n, n = list_entry(n->member.next, typeof(*n), member))
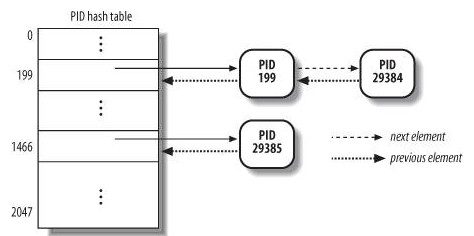
structpid { /* Try to keep pid_chain in the same cacheline as nr for find_pid */ /** * PID值。 */ int nr; /** * 链接散列表中下一个和前一个元素。 */ structhlist_node pid_chain; /* list of pids with the same nr, only one of them is in the hash */ /** * 每个PID的进程链表头。 */ structlist_head pid_list; };